
This is a detailed tutorial to read and write CSV files in Python. Learn to parse CSV files with the inbuilt Python Library and also with the Pandas library.
Understanding the CSV Files
CSV is one of the most popular formats around the globe to keep, exchange, and process information at various levels. CSV stands for Comma Separated Values. It is basically a text file that stores tabular data. Like every other textual file, the data characters written in these files are also readable ASCII or Unicode characters. Each line of this file represents a single table row and to separate the column values, commas are used.
In CSV, the comma is the separation symbol while there are several other similar formats that use different separation symbols. One such example is TSV (TAB Separated Values) which makes use of tabular space (\t) to separate columns. The separation symbols are known as delimiters. Colon (:) and Semi-Colon (;) are two other popular delimiters.
A CSV file may look like the following.
column 1, column 2, column 3 row 1 col 1, row 1 col 2, row 1 col 3 row 2 col 1, row 2 col 2, row 2 col 3 ...
The first row of the CSV file is usually used for the column names but it is not at all necessary. You should also understand the importance of delimiter symbols. These symbols should not actually match with any character that the actual data contain in the row and column values. If it matches it, it may actually break the file.
Now, what if you wanted to save a column value that contains a comma (‘) itself?
column 1, column 2, column 3 row 1 col 1,"row 1, col 2", row 1 col 3 row 2 col 1, row 2 col 2, row 2 col 3
In such a case, other symbols like quotes are used to keep the CSV file valid. As you can see in the above format, the second row and second column value contain a comma, therefore it is enclosed within double quotes. Now, if the value will be containing a double quote itself, then it either has to be enclosed by some other character or one or more double quotes has to be appended to keep the column valid. Find more about CSV Files here.
Therefore in the case of large CSV files with lots of such data, manual management is difficult. So, let’s learn how you can use Python to handle the writing and reading operation on a CSV file.
Using Python’s Built-in Library For CSV File Parsing
Python comes with a pre-installed library to parse CSV files. This library can be used to read as well as to write CSV files. This library has been extensively designed not just to work for one single format but for various other CSV formats as well. Even it is capable of being used for parsing Excel Generated files. Therefore, this library contains all the powerful tools to read and create CSV files of all types.
Reading Files With CSV Library
This library provides an object named reader that can be used to read files from an existing valid .csv file. Before we can read the file using the reader object, we’ll first need to open the file. We can use another built-in Python function open() for the purpose. Using this function we can read any file with any extension, provided the contents are textual.
Once, we open the file, we’ve to pass it as the first argument to the reader() object. This object also takes a second parameter. It is the delimiter. You’ve to specify the symbol with which you’re separating the values in the file. As we’re working with CSV files, we’ll specify the delimiter here to be a comma.
For demonstration, we’ve taken a sample CSV file employees.csv, the contents of which are written below.
emp_no,birth_date,first_name,last_name,gender,hire_date 10001,9/2/1953,Georgi,Facello,M,6/26/1986 10003,12/3/1959,Parto,Bamford,M,8/28/1986 10005,1/21/1955,Kyoichi,Maliniak,M,9/12/1989 10006,4/20/1953,Anneke,Preusig,F,6/2/1989 10007,5/23/1957,Tzvetan,Zielinski,F,2/10/1989 10008,2/19/1958,Saniya,Kalloufi,M,9/15/1994 10009,4/19/1952,Sumant,Peac,F,2/18/1985 10010,6/1/1963,Duangkaew,Piveteau,F,8/24/1989 10011,11/7/1953,Mary,Sluis,F,1/22/1990 10012,10/4/1960,Patricio,Bridgland,M,12/18/1992
The Python code to read the above file using Python’s inbuilt CSV library is also written below.
import csv
with open('employees.csv') as file:
csvFile = csv.reader(file, delimiter=',')
line_no = 0
for row in csvFile:
if line_no == 0:
print("Column Names: " + " ".join(row))
else:
print("ROW " + str(line_no) + ": " + " ".join(row))
line_no += 1
The output of the above code is shown in the screenshot given below.
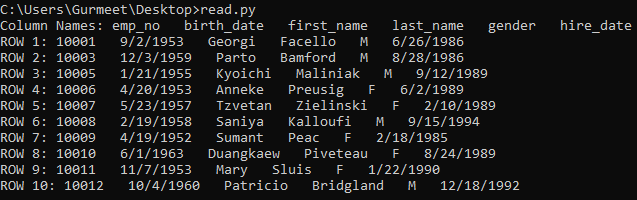
Let’s understand the code. First of all, we’re importing the CSV module. Then using the Python open() function, we’re loading the file employees.csv into the file variable. Then we’re parsing the file variable as a CSV file using the reader object of the CSV module. Then, we’re just iterating csvFile variable using Python For Loop.
With every iteration, the variable row will be a Python List that will contain all the column values for that current row. You can fetch the value of any particular column using indexes on the list variable. For example, row[0] for the first, row[1] for the second column value for the current row, and so on.
Reading CSV File Into Python Dictionary
The code in the above section will read the CSV file and loads it into the csvFile variable. reader Object is the data type of this variable. Iterating and fetching the different column and row values using the above method is good when you do not have to further perform complex operations on the data. But it is not the recommended way in most the cases.
There’s a more suitable way and that is reading the CSV files and loading them directly into a Python Dictionary object. This makes the row and column values more readable. You can access any cell of the CSV file tabular data by just knowing the column name for a particular iteration. If you will use the reader object method then you have to know the column index for a particular iteration.
Instead of the reader object, here we’ll use the DictReader object of the CSV module. The code demonstrating the same is written below.
import csv
with open('employees.csv') as file:
csvFile = csv.DictReader(file, delimiter=',')
line_no = 1
for row in csvFile:
print("ROW " + str(line_no) + ": " + row["emp_no"] + " " + row["birth_date"] + " " + row["first_name"] + " " + row["last_name"] + " " + row["gender"] + " " + row["hire_date"])
line_no += 1
The following screenshot displays the output of the above code.
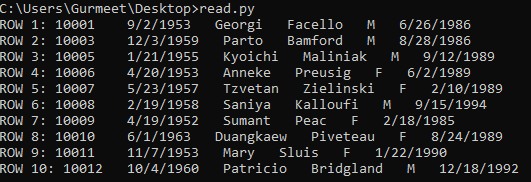
Note. Also notice once more the difference between the two methods. When you iterate the reader object, the first row is going to be the column names row while iterating the DictReader object, the first row is the row of values itself. It automatically assumes the first row of the CSV files as column names for creating the dictionary and in the DictReader object, therefore, the first-row id row values rather than the column names.
Now, that you know the difference between the two methods and working, you can use any of these as per your requirement and use case.
Optional Parameters For Complex CSV File Readings
You can parse different types and styles of CSV and other textual files by providing the required extra information as additional parameters to the reader object. These parameters are listed below in tabular form with a description of each of them.
| Parameter | Description |
delimiter |
You can specify a symbol in this parameter that is being used in the file to separate the different columns and values. The default value of this parameter is a comma. (,) Example. delimiter = ';' |
quotechar |
As discussed at the very start of this article some of the CSV files with complex data may contain characters in the data that are also used as file delimiters. So, in such cases enclosing symbols like double quotes are used to specify the column value starting and ending. That enclosing symbol can be specified in the quotechar parameter. The default value of this parameter is a double quote. (") Example. quotechar = '|' |
escapecar |
Escape characters are used when quotes are not used to escape the delimiter character. There is no escape character parameter value set by default. |
Consider the following file, employees.txt. It contains values that are separated by semi-colons as commas are used to separate the first and last name itself. Also, for the last column salary_code the delimiter character (;) is used as the value. Therefore, the enclosing character (|) is also used.
emp_no;birth_date;first_name,last_name;gender;hire_date;salary_code 10001;9/2/1953;Georgi,Facello;M;6/26/1986;|A;45| 10003;12/3/1959;Parto,Bamford;M;8/28/1986;|A;45| 10005;1/21/1955;Kyoichi,Maliniak;M;9/12/1989;|A;47| 10006;4/20/1953;Anneke,Preusig;F;6/2/1989;|A;35| 10007;5/23/1957;Tzvetan,Zielinski;F;2/10/1989;|A;45|
So, in order to read this file, you’ve to specify the delimiter parameter as ';' and quotechar as '|'.
The following code illustrated the concept of reading the above file by providing extra parameter values.
import csv
with open('employees.txt') as file:
csvFile = csv.DictReader(file, delimiter=';', quotechar = '|')
line_no = 1
for row in csvFile:
print("ROW " + str(line_no) + ": " + row["emp_no"] + " " + row["birth_date"] + " " + row["first_name,last_name"] + row["gender"] + " " + row["hire_date"])
line_no += 1
The output screenshot shows that the above code reads the file with custom delimiters and enclosing symbols perfectly.
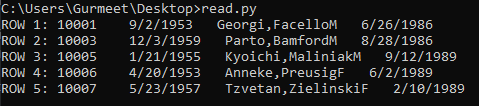
Writing Files With CSV Library
So, till now, we’ve learned how to read CSV files and now let’s begin with the writing part of the story. Before we can start writing, we’ve to open a file on which we can write the CSV data. Again, using the Python inbuilt function open(), this can be done. You must set the mode of this function as 'w' to enable file writing.
Have a look at the code and then we’ll understand how it works.
import csv
with open('employees_created.csv', mode='w') as file:
csvFile = csv.DictWriter(file, fieldnames=['emp_no', 'salary'])
csvFile.writeheader()
csvFile.writerow({'emp_no': '10001', 'salary': '45000'})
csvFile.writerow({'emp_no': '10002', 'salary': '48000'})
csvFile.writerow({'emp_no': '10003', 'salary': '47500'})
csvFile.writerow({'emp_no': '10004', 'salary': '42500'})
csvFile.writerow({'emp_no': '10004', 'salary': '50000'})
The above code will create a file named employees_created.csv, the data of which is given below.
emp_no,salary 10001,45000 10002,48000 10003,47500 10004,42500 10004,50000
As the DictReader object is used for reading, the DictWriter object is used for writing the CSV files. You require to give two parameters to this function, one is the file to which you want to write and the other is the fieldnames which is basically a list object of column names.
In case you have commas or quotes in your values, this function will automatically do the necessary addition of escaping but you can also provide you custom escaping character using the quotechar parameter.
Using Pandas Library For CSV File Parsing
When you want to parse CSV files in Python for advanced purposes like Machine Learning, you should not simply go with the basic reading and writing approach as discussed in the above section. Rather, you should use a library like Pandas for doing a lot more with the CSV data! Especially if you are doing data analysis and have lots of data, this is the recommended option.
Pandas is basically an open-source library that can be used for data analyses. It also provides easy-to-use and high-perform data structures for better analysis of the data. It is much more than just working with CSV files. Find more about it here. We need not go dig deeper into Pandas to use its CSV reading and writing feature.
Make sure you have the pandas library installed. If not, you can quickly install it using PIP. Just run the following command to install it.
pip install pandas
Pandas Reading CSV Files
Reading CSVs with Pandas is actually quite easy and you can do it in just 2 or 3 short lines of code. Consider the same employees.csv file that we’ve used in the previous examples.
emp_no,birth_date,first_name,last_name,gender,hire_date 10001,9/2/1953,Georgi,Facello,M,6/26/1986 10003,12/3/1959,Parto,Bamford,M,8/28/1986 10005,1/21/1955,Kyoichi,Maliniak,M,9/12/1989 10006,4/20/1953,Anneke,Preusig,F,6/2/1989 10007,5/23/1957,Tzvetan,Zielinski,F,2/10/1989 10008,2/19/1958,Saniya,Kalloufi,M,9/15/1994 10009,4/19/1952,Sumant,Peac,F,2/18/1985 10010,6/1/1963,Duangkaew,Piveteau,F,8/24/1989 10011,11/7/1953,Mary,Sluis,F,1/22/1990 10012,10/4/1960,Patricio,Bridgland,M,12/18/1992
The following code will read this file and after loading it into a pandas DataFrame, it will print it on the output screen, as shown in the screenshot after it.
import pandas
csv = pandas.read_csv('employees.csv')
print(csv)
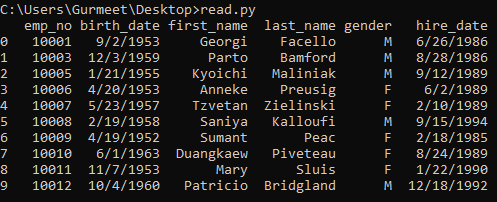
The read_csv() object of the pandas library does a lot of stuff itself. It identifies the first line of the file as the column names and it automatically assigns indexes to each and every row as you can see from 0 to 9 in the above screenshot. These are really useful when you quickly wanted to fetch the value for a particular column and row of the entire tabular data of the CSV file.
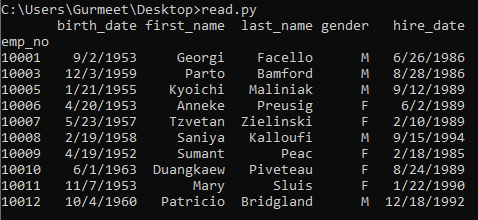
If you do not want the indices, you’ve to specify any other column as an index column. You can do this by specifying a column in the index_col parameter of the read_csv() object.
import pandas
csv = pandas.read_csv('employees.csv', index_col = 'emp_no')
print(csv)
Pandas also ensure the data types of the column values. If there are numerical values, pandas is enough intelligent to differentiate them as numerical values from the other string-based values. Let check. The value of the column emp_no for any row should be an integer while for first_name it should be a string-type object.
import pandas
csv = pandas.read_csv('employees.csv')
print(type(csv['emp_no'][0]))
print(type(csv['first_name'][0]))
print(type(csv['birth_date'][0]))
The above code basically checks the data type of the first three columns of the first row of the CSV file, employees.csv.
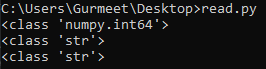
You can see it has detected the data type as an integer for the column emp_no and string for the column first_name. But it is still considering the birth_date the column value as a string, rather it should also identify it as the date data type. You can make sure the correct data type for this column by adding an additional parameter parse_dates. You have to provide a list of columns that should be of the date data type. The following code and output illustrate the same.
import pandas
csv = pandas.read_csv('employees.csv', parse_dates=['birth_date','hire_date'])
print(type(csv['birth_date'][0]))
print(type(csv['hire_date'][0]))

Another case could be the first line of the CSV file may not contain the column names. So, Pandas also provide the feature that you can specify the column names in the code for any CSV file that you want to load and read.
import pandas
columns = ['Employee Number', 'Birth Date', 'First Name', 'Last Name', 'Gender', 'Hire Date']
csv = pandas.read_csv('employees.csv', names = columns, index_col = 'Employee Number', parse_dates = ['Birth Date', 'Hire Date'])
print(csv)
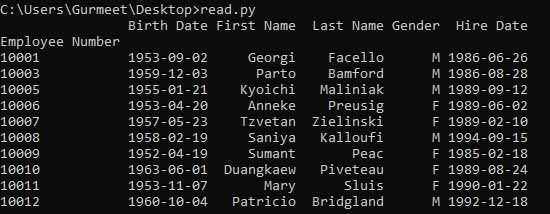
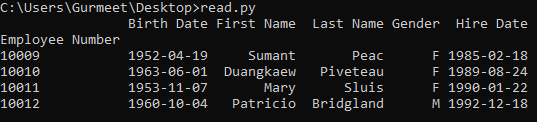
You can also specify a parameter named header, it can take numerical values starting from 0 and so on. The first row is numbered 0 and in the growing order the other rows. So, with this parameter, you can specify from which row it should start reading the CSV file.
import pandas
columns = ['Employee Number', 'Birth Date', 'First Name', 'Last Name', 'Gender', 'Hire Date']
csv = pandas.read_csv('employees.csv', header= 5, names = columns, index_col = 'Employee Number', parse_dates = ['Birth Date', 'Hire Date'])
print(csv)
As you can see in the following screenshot, the header parameter is set to 5 and there is no column row in the CSV file, so it starts reading the CSV file from line number 7. (Its index also starts from 0 and one is the header row).
Pandas Writing CSV Files
As Pandas read the CSV file into a Pandas DataFrame, therefore in order to write files using Pandas, you’ve to provide it the data in the form of Pandas DataFrame format. The following Python code first read the file employees.csv and then after converting it into Pandas DataFrame, it writes the same into a new CSV file, employees_new_column_names.csv.
import pandas
columns = ['Employee Number', 'Birth Date', 'First Name', 'Last Name', 'Gender', 'Hire Date']
csv = pandas.read_csv('employees.csv', index_col = 'Employee Number', parse_dates = ['Birth Date','Hire Date'], header = 0, names = columns)
csv.to_csv('employees_new_column_names.csv')


 Function")

 Method – Tutorial with Examples")
