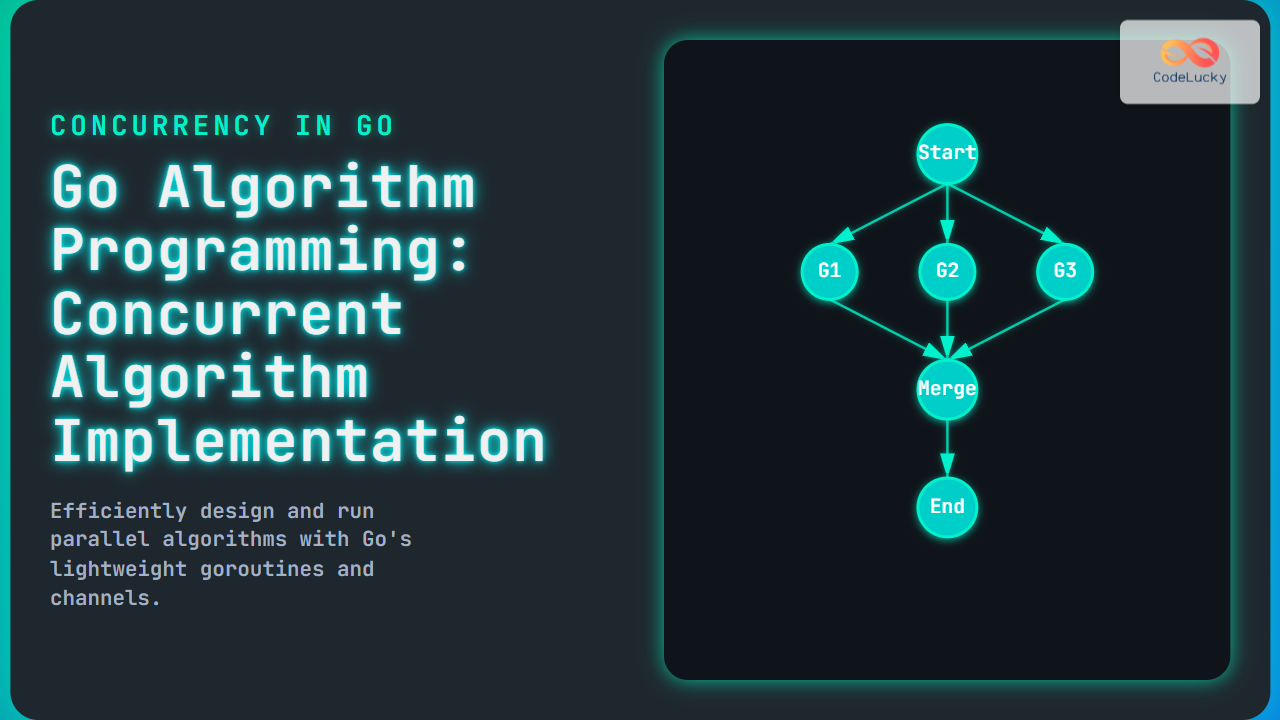
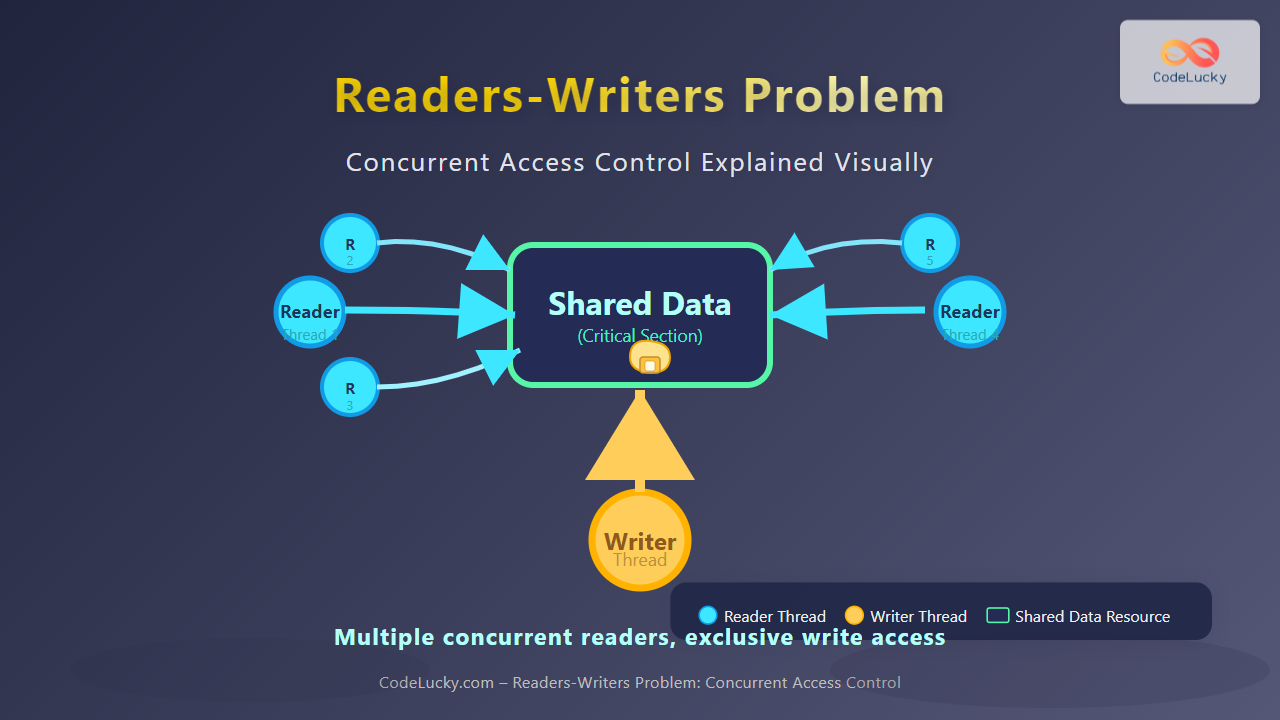
The Readers Writers Problem is one of the most fundamental synchronization challenges in operating systems and database management. This classic concurrency problem addresses how multiple processes can safely access a shared resource, where some processes only read data while others modify it.
Understanding the Readers Writers Problem
In database systems, we often encounter scenarios where multiple users need to access the same data simultaneously. Readers perform read-only operations that don’t modify the data, while Writers perform operations that change the data state.
Key Constraints
- Multiple readers can access the resource simultaneously since reading doesn’t alter data
- Only one writer can access the resource at a time
- No reader and writer can access the resource simultaneously
- Writers have exclusive access when modifying data

Problem Variations
The Readers Writers Problem has three main variations, each prioritizing different types of operations:
1. First Readers Writers Problem (Readers Priority)
In this variation, readers have priority over writers. New readers can join even if a writer is waiting, potentially causing writer starvation.
2. Second Readers Writers Problem (Writers Priority)
Here, writers have priority over readers. Once a writer requests access, no new readers are allowed until the writer completes, preventing reader starvation but potentially starving readers.
3. Third Readers Writers Problem (Fair Solution)
This approach ensures fairness by preventing both reader and writer starvation through balanced scheduling.
Solution Using Semaphores
Let’s implement the classic solution using semaphores and mutex locks:
Shared Variables
// Shared variables
int readCount = 0; // Number of active readers
semaphore mutex = 1; // Protects readCount
semaphore writeBlock = 1; // Controls writer access
Reader Process Implementation
void reader() {
while (true) {
// Entry section
wait(mutex); // Lock readCount
readCount++;
if (readCount == 1) {
wait(writeBlock); // First reader blocks writers
}
signal(mutex); // Release readCount lock
// Critical section - Reading
printf("Reader %d is reading data\n", reader_id);
performReadOperation();
// Exit section
wait(mutex); // Lock readCount
readCount--;
if (readCount == 0) {
signal(writeBlock); // Last reader unblocks writers
}
signal(mutex); // Release readCount lock
// Non-critical section
doOtherWork();
}
}
Writer Process Implementation
void writer() {
while (true) {
// Entry section
wait(writeBlock); // Get exclusive access
// Critical section - Writing
printf("Writer %d is writing data\n", writer_id);
performWriteOperation();
// Exit section
signal(writeBlock); // Release exclusive access
// Non-critical section
doOtherWork();
}
}

Advanced Solution: Writers Priority
To prevent writer starvation, we can implement a writers priority solution:
// Additional shared variables for writers priority
int writeCount = 0; // Number of waiting writers
semaphore readBlock = 1; // Blocks new readers when writers wait
semaphore writeMutex = 1; // Protects writeCount
Enhanced Reader Process
void prioritizedReader() {
while (true) {
// Entry section
wait(readBlock); // Check if writers are waiting
wait(mutex);
readCount++;
if (readCount == 1) {
wait(writeBlock);
}
signal(mutex);
signal(readBlock);
// Critical section
performReadOperation();
// Exit section
wait(mutex);
readCount--;
if (readCount == 0) {
signal(writeBlock);
}
signal(mutex);
doOtherWork();
}
}
Enhanced Writer Process
void prioritizedWriter() {
while (true) {
// Entry section
wait(writeMutex);
writeCount++;
if (writeCount == 1) {
wait(readBlock); // Block new readers
}
signal(writeMutex);
wait(writeBlock); // Get exclusive access
// Critical section
performWriteOperation();
// Exit section
signal(writeBlock);
wait(writeMutex);
writeCount--;
if (writeCount == 0) {
signal(readBlock); // Allow readers again
}
signal(writeMutex);
doOtherWork();
}
}
Database Implementation Example
Here’s a practical example demonstrating the Readers Writers Problem in a database context:
import threading
import time
import random
class Database:
def __init__(self):
self.data = {"balance": 1000, "transactions": []}
self.read_count = 0
self.mutex = threading.Lock() # Protects read_count
self.write_lock = threading.Lock() # Controls write access
def read_data(self, reader_id):
# Reader entry
with self.mutex:
self.read_count += 1
if self.read_count == 1:
self.write_lock.acquire() # First reader blocks writers
# Reading operation
print(f"Reader {reader_id}: Current balance = ${self.data['balance']}")
print(f"Reader {reader_id}: Transaction count = {len(self.data['transactions'])}")
time.sleep(random.uniform(0.1, 0.5)) # Simulate read time
# Reader exit
with self.mutex:
self.read_count -= 1
if self.read_count == 0:
self.write_lock.release() # Last reader unblocks writers
def write_data(self, writer_id, amount):
# Writer entry
self.write_lock.acquire()
# Writing operation
old_balance = self.data['balance']
self.data['balance'] += amount
self.data['transactions'].append({
'writer': writer_id,
'amount': amount,
'timestamp': time.time()
})
print(f"Writer {writer_id}: Updated balance from ${old_balance} to ${self.data['balance']}")
time.sleep(random.uniform(0.2, 0.8)) # Simulate write time
# Writer exit
self.write_lock.release()
# Example usage
db = Database()
def reader_thread(reader_id):
for _ in range(3):
db.read_data(reader_id)
time.sleep(random.uniform(0.1, 1.0))
def writer_thread(writer_id):
for _ in range(2):
amount = random.randint(-100, 200)
db.write_data(writer_id, amount)
time.sleep(random.uniform(0.5, 1.5))
# Create threads
threads = []
for i in range(3):
threads.append(threading.Thread(target=reader_thread, args=(f"R{i+1}",)))
for i in range(2):
threads.append(threading.Thread(target=writer_thread, args=(f"W{i+1}",)))
# Start all threads
for thread in threads:
thread.start()
for thread in threads:
thread.join()
Expected Output
Reader R1: Current balance = $1000
Reader R1: Transaction count = 0
Reader R2: Current balance = $1000
Reader R2: Transaction count = 0
Writer W1: Updated balance from $1000 to $1150
Reader R3: Current balance = $1150
Reader R3: Transaction count = 1
Writer W2: Updated balance from $1150 to $1050
Reader R1: Current balance = $1050
Reader R1: Transaction count = 2

Performance Considerations
When implementing the Readers Writers Problem in production systems, consider these performance factors:
Throughput Optimization
- Read-heavy workloads benefit from readers priority implementation
- Write-heavy workloads require writers priority to prevent data staleness
- Mixed workloads need fair scheduling algorithms
Starvation Prevention
// Fair solution using timestamps
typedef struct {
int process_id;
timestamp_t arrival_time;
process_type_t type; // READER or WRITER
} ProcessRequest;
// Priority queue ordered by arrival time
PriorityQueue* request_queue;
void fairScheduler() {
while (!isEmpty(request_queue)) {
ProcessRequest* next = dequeue(request_queue);
if (next->type == READER) {
// Allow reader if no writers are active
if (active_writers == 0) {
grantReaderAccess(next->process_id);
} else {
// Re-queue if writer is active
enqueue(request_queue, next);
}
} else {
// Allow writer if no readers or writers are active
if (active_readers == 0 && active_writers == 0) {
grantWriterAccess(next->process_id);
} else {
enqueue(request_queue, next);
}
}
}
}
Real-World Applications
Database Management Systems
Modern databases use sophisticated implementations of the Readers Writers Problem:
- MySQL InnoDB uses Multi-Version Concurrency Control (MVCC)
- PostgreSQL implements snapshot isolation for readers
- Oracle uses read consistency through undo segments
File Systems
Operating systems apply similar principles for file access:
// File access control structure
typedef struct {
int read_locks;
int write_locks;
pthread_mutex_t lock_mutex;
pthread_cond_t read_cond;
pthread_cond_t write_cond;
} FileAccessControl;
int acquireReadLock(FileAccessControl* fac) {
pthread_mutex_lock(&fac->lock_mutex);
while (fac->write_locks > 0) {
pthread_cond_wait(&fac->read_cond, &fac->lock_mutex);
}
fac->read_locks++;
pthread_mutex_unlock(&fac->lock_mutex);
return 0;
}
int acquireWriteLock(FileAccessControl* fac) {
pthread_mutex_lock(&fac->lock_mutex);
while (fac->read_locks > 0 || fac->write_locks > 0) {
pthread_cond_wait(&fac->write_cond, &fac->lock_mutex);
}
fac->write_locks++;
pthread_mutex_unlock(&fac->lock_mutex);
return 0;
}

Common Pitfalls and Solutions
Deadlock Prevention
Avoid deadlock situations by maintaining consistent lock ordering:
// Incorrect - potential deadlock
void badImplementation() {
wait(lockA);
wait(lockB);
// Critical section
signal(lockB);
signal(lockA);
}
// Correct - consistent ordering
void goodImplementation() {
// Always acquire locks in the same order
if (lockA_id < lockB_id) {
wait(lockA);
wait(lockB);
} else {
wait(lockB);
wait(lockA);
}
// Critical section
// Release in reverse order
signal(lockB);
signal(lockA);
}
Race Condition Prevention
- Atomic operations for counter updates
- Proper synchronization in entry and exit sections
- Memory barriers to ensure ordering
Modern Alternatives
Read-Write Locks (pthread_rwlock)
#include
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;
// Reader
void* reader_function(void* arg) {
pthread_rwlock_rdlock(&rwlock);
// Read operations
printf("Reading data...\n");
pthread_rwlock_unlock(&rwlock);
return NULL;
}
// Writer
void* writer_function(void* arg) {
pthread_rwlock_wrlock(&rwlock);
// Write operations
printf("Writing data...\n");
pthread_rwlock_unlock(&rwlock);
return NULL;
}
Lock-Free Programming
Advanced systems use lock-free data structures and atomic operations:
#include
typedef struct Node {
atomic_int data;
struct Node* next;
} Node;
// Lock-free read
int lockFreeRead(Node* head, int index) {
Node* current = head;
for (int i = 0; i < index && current; i++) {
current = current->next;
}
return current ? atomic_load(¤t->data) : -1;
}
// Compare-and-swap write
bool lockFreeWrite(Node* node, int expected, int new_value) {
return atomic_compare_exchange_strong(&node->data, &expected, new_value);
}
Testing and Debugging
Effective testing strategies for Readers Writers implementations:
import threading
import time
import random
from concurrent.futures import ThreadPoolExecutor
def stress_test_readers_writers():
db = Database()
results = {'reads': 0, 'writes': 0, 'errors': 0}
def reader_stress():
try:
for _ in range(100):
db.read_data(threading.current_thread().ident)
results['reads'] += 1
time.sleep(random.uniform(0.001, 0.01))
except Exception:
results['errors'] += 1
def writer_stress():
try:
for _ in range(50):
amount = random.randint(-50, 100)
db.write_data(threading.current_thread().ident, amount)
results['writes'] += 1
time.sleep(random.uniform(0.005, 0.02))
except Exception:
results['errors'] += 1
# Run stress test
with ThreadPoolExecutor(max_workers=20) as executor:
# Submit reader tasks
reader_futures = [executor.submit(reader_stress) for _ in range(15)]
# Submit writer tasks
writer_futures = [executor.submit(writer_stress) for _ in range(5)]
# Wait for completion
for future in reader_futures + writer_futures:
future.result()
print(f"Test Results: {results['reads']} reads, {results['writes']} writes, {results['errors']} errors")
return results['errors'] == 0
# Run the test
test_passed = stress_test_readers_writers()
print(f"Stress test {'PASSED' if test_passed else 'FAILED'}")
Best Practices
Follow these guidelines for robust implementations:
Design Principles
- Minimize critical sections to reduce lock contention
- Use appropriate lock granularity – not too coarse, not too fine
- Implement timeout mechanisms to prevent indefinite blocking
- Monitor performance metrics like lock wait time and throughput
Code Quality
- Clear variable naming for synchronization primitives
- Comprehensive error handling for lock operations
- Detailed logging for debugging race conditions
- Unit tests covering concurrent scenarios
The Readers Writers Problem remains crucial for understanding database synchronization and concurrent programming. Modern implementations leverage advanced techniques like MVCC and lock-free algorithms, but the fundamental principles continue to guide system design decisions in database management, file systems, and distributed computing environments.
Related Posts

Thread Synchronization: Mutexes, Semaphores and Deadlocks in Operating Systems
Introduction to Thread Synchronization Thread synchronization is a fundamental concept in operating systems that ensures multiple threads can safely access...
Producer Consumer Problem: Complete Guide to Bounded Buffer Implementation with Code Examples
The Producer Consumer Problem, also known as the bounded buffer problem, is one of the most fundamental synchronization problems in...

Process Synchronization: Critical Sections and Race Conditions in Operating Systems
Introduction to Process Synchronization Process synchronization is a fundamental concept in operating systems that ensures multiple processes can safely access...

Lamport’s Bakery Algorithm: Complete Guide to N-Process Mutual Exclusion
Lamport's Bakery Algorithm stands as one of the most elegant solutions to the N-process mutual exclusion problem in concurrent programming....

Critical Section Problem: Complete Guide to Mutual Exclusion Solutions in Operating Systems
What is the Critical Section Problem? The critical section problem is a fundamental challenge in operating systems where multiple processes...

File Locking Mechanisms: Complete Guide to Advisory and Mandatory Locking in Operating Systems
File locking mechanisms are essential components of modern operating systems that prevent data corruption and ensure data integrity when multiple...
Monitor in Operating System: High-level Synchronization for Process Coordination
What is a Monitor in Operating System? A monitor is a high-level synchronization construct in operating systems that provides a...

SQL Table Locking: Managing Concurrent Access
In the world of database management, ensuring data integrity while allowing multiple users to access and modify data simultaneously is...

Mutex vs Semaphore: Complete Guide to Synchronization Primitives in Operating Systems
In the world of concurrent programming and operating systems, synchronization primitives are essential tools that prevent race conditions and ensure...
Thread vs Process: Complete Guide to Differences and When to Use Each
Understanding the fundamental differences between threads and processes is crucial for system programming, application design, and performance optimization. While both...

Binary Semaphore: Complete Guide to Mutual Exclusion Implementation in Operating Systems
What is a Binary Semaphore? A binary semaphore is a synchronization primitive in operating systems that can hold only two...

C++ Thread Synchronization: Mutexes and Locks
In the world of modern C++ programming, multithreading has become an essential technique for improving application performance and responsiveness. However,...