Picture this: your side project just hit the front page of a tech community, traffic is spiking, and your database is buckling under the load. In that moment, the choice you made months earlier — SQL vs NoSQL — suddenly matters more than any line of application code you wrote. Pick the right database and scaling feels almost boring. Pick the wrong one and you are rewriting your data layer at 2 a.m.
The good news is that this decision is far less mysterious than online debates make it sound. Once you understand how each model actually stores and retrieves data, the right answer for your use case usually becomes obvious. This guide breaks down the SQL vs NoSQL question for 2026, with real examples, honest trade-offs, and a practical framework you can apply today.
What Is the Difference Between SQL and NoSQL?
SQL databases are relational: they store data in tables made of rows and columns, with a fixed schema and relationships enforced between tables. NoSQL databases are non-relational: they store data in flexible formats like documents, key-value pairs, wide columns, or graphs, usually without a rigid schema. SQL prioritizes consistency and structure; NoSQL prioritizes flexibility and horizontal scale.
That single distinction — rigid structure versus flexible structure — drives almost every other difference you will encounter. SQL forces you to define your data shape up front. NoSQL lets you defer those decisions, which is a blessing early on and occasionally a curse later.
Both families are mature, battle-tested, and used by companies of every size. The SQL vs NoSQL choice is not about old versus new or good versus bad. It is about matching a data model to a problem.
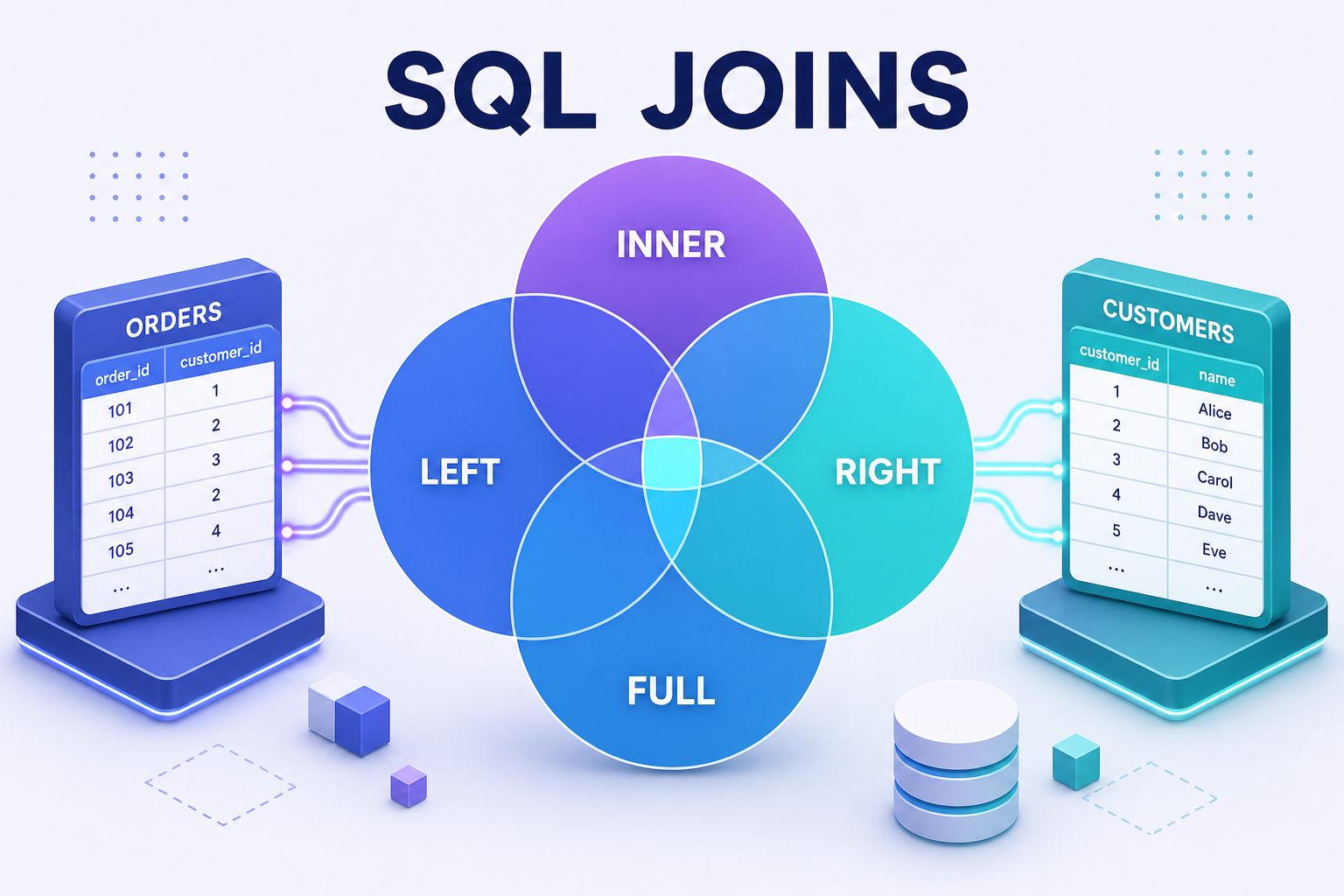
How SQL Databases Work
A SQL (Structured Query Language) database organizes information into tables. Each table has a defined schema — a contract that specifies column names and data types. Rows in one table connect to rows in another through foreign keys, which is where the term “relational” comes from.
Imagine a spreadsheet, but one that refuses to let you put text in a number column and can instantly join data across dozens of sheets. Popular relational databases include PostgreSQL, MySQL, SQLite, and Microsoft SQL Server.
Here is what a simple relational query looks like. Suppose you have a users table and an orders table, and you want every order placed by a specific customer:
-- Join two related tables on a shared key
SELECT users.name, orders.total, orders.created_at
FROM users
INNER JOIN orders ON orders.user_id = users.id -- link orders to their owner
WHERE users.email = '[email protected]'
ORDER BY orders.created_at DESC;This query pulls a user’s name and stitches it together with their orders in one round trip. The database guarantees that every orders.user_id actually points to a real user, so you never end up with an orphaned order belonging to nobody. That referential integrity is one of SQL’s superpowers.
ACID and Why Transactions Matter
Relational databases are famous for ACID guarantees: Atomicity, Consistency, Isolation, and Durability. In plain terms, a transaction either fully happens or fully fails, and your data never lands in a half-broken state.
This is non-negotiable for money. If you move $100 between two bank accounts, you cannot have the debit succeed while the credit fails. A transaction wraps both operations so they commit together or roll back together:
BEGIN; -- start the transaction
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT; -- both updates apply, or neither doesIf the database crashes between the two updates, ACID durability ensures the system recovers without losing or duplicating that $100. For financial, inventory, or booking systems, this safety net is exactly why teams reach for SQL first.
How NoSQL Databases Work
NoSQL (“Not Only SQL”) is an umbrella term for databases that ditch the rigid table model. Instead of one shape, there are several, each tuned for a different access pattern. Understanding these categories is the key to the SQL vs NoSQL decision.
- Document stores — data lives in JSON-like documents. Great for nested, evolving data. Example: MongoDB.
- Key-value stores — a giant, blazing-fast dictionary. Example: Redis, DynamoDB.
- Wide-column stores — rows with dynamic columns, built for massive write throughput. Example: Apache Cassandra.
- Graph databases — nodes and edges for highly connected data. Example: Neo4j.
Document databases are the most common starting point. Here is how you might store and query a user profile in MongoDB using its Node.js driver:
// A single document holds the user AND their nested addresses
await db.collection('users').insertOne({
name: 'Alex Rivera',
email: '[email protected]',
addresses: [ // nested array, no separate table needed
{ type: 'home', city: 'Austin' },
{ type: 'work', city: 'Dallas' }
]
});
// Find users who have a work address in Dallas
const result = await db.collection('users').find({
'addresses.type': 'work',
'addresses.city': 'Dallas'
}).toArray();Notice there is no JOIN and no separate addresses table. The entire profile, including its nested addresses, sits inside one document. This makes reads fast because everything you need arrives together, and it lets each user document have a slightly different shape without breaking anything.
The mental shift with NoSQL is this: instead of normalizing data into many tidy tables, you model it around how your application reads it. You optimize for queries, not for theoretical purity.
SQL vs NoSQL: Key Differences Compared
Side by side, the contrasts in the SQL vs NoSQL comparison become much clearer. The table below summarizes the practical trade-offs you will weigh on most projects.
| Dimension | SQL (Relational) | NoSQL (Non-Relational) |
|---|---|---|
| Data model | Tables, rows, columns | Documents, key-value, graph, wide-column |
| Schema | Fixed, defined up front | Flexible, dynamic |
| Scaling | Primarily vertical (bigger server) | Primarily horizontal (more servers) |
| Consistency | Strong (ACID) | Often eventual (BASE), tunable |
| Query language | Standardized SQL | Database-specific APIs |
| Best for | Complex queries, transactions, structured data | High volume, evolving or unstructured data |
One row deserves a closer look: scaling. SQL databases traditionally scale up by adding CPU, RAM, and faster disks to a single machine. NoSQL databases were designed to scale out by distributing data across many cheaper machines. As you will see, that gap has narrowed dramatically in 2026.
When to Use SQL
Reach for a relational database when your data is structured, relationships matter, and correctness is critical. SQL shines in these scenarios:
- Financial systems, e-commerce checkouts, and anything touching money
- Applications with complex queries joining many entities
- Reporting and analytics where ad-hoc questions are common
- Data with clear, stable structure that rarely changes shape
- Teams that value strong consistency over raw write speed
If you are not sure which side of the SQL vs NoSQL line your project falls on, a relational database like PostgreSQL is a safe default. It handles structured data beautifully and, thanks to native JSON columns, can even store flexible document-style data when you need it:
-- PostgreSQL can store flexible JSON inside a relational table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
attributes JSONB -- schemaless field for varying product specs
);
-- Query into the JSON document directly
SELECT name FROM products
WHERE attributes ->> 'color' = 'blue';This hybrid ability is why “just start with Postgres” is common advice in 2026. You get strict structure where you need it and flexible storage where you do not, all inside one ACID-compliant system.
When to Use NoSQL
Choose NoSQL when flexibility, scale, or specific access patterns dominate your requirements. Strong fits include:
- Real-time apps with huge write volumes (chat, IoT sensors, activity feeds)
- Content and catalogs where each item has different fields
- Caching and session storage that demand sub-millisecond reads (key-value)
- Recommendation engines and social graphs (graph databases)
- Rapid prototyping where the schema is still in flux
The flexibility cuts both ways, though. Because NoSQL does not enforce a schema, your application becomes responsible for keeping data clean. A typo in a field name will not throw an error; it will quietly create a new field. Discipline in your code replaces discipline in the database.
SQL vs NoSQL in 2026: What Has Actually Changed
The old SQL vs NoSQL battle lines have blurred. The two camps borrowed each other’s best ideas, and several trends now shape the modern decision.
Distributed SQL closed the scaling gap
Databases like CockroachDB, Google Spanner, and YugabyteDB deliver the horizontal scaling that once belonged only to NoSQL — while keeping full ACID transactions and standard SQL. The “SQL can’t scale” argument is largely outdated. If you need both global scale and strong consistency, distributed SQL is now a serious option.
NoSQL got transactions and structure
Meanwhile, MongoDB added multi-document ACID transactions, and many NoSQL engines now offer optional schema validation. The line between the families is thinner than it has ever been.
Vector search became a first-class feature
With AI applications everywhere, storing and querying embeddings is now standard. PostgreSQL gained pgvector, and document stores added native vector indexes. You no longer have to choose a separate database just to power semantic search or retrieval-augmented generation.
The takeaway: in 2026, the SQL vs NoSQL choice is less about hard limits and more about which tool gives you the smoothest path for your specific workload and team.
Common Pitfalls to Avoid
Even experienced developers stumble on the same database mistakes. Watch out for these.
- Choosing NoSQL for “scale” you do not have. Most apps never outgrow a well-indexed relational database. Premature scaling adds complexity for an audience that may never arrive.
- Forcing relational data into documents. If your data is full of many-to-many relationships, fighting against joins in a document store leads to painful, duplicated data.
- Ignoring indexes. Both SQL and NoSQL slow to a crawl without proper indexes. A missing index, not the database type, is the most common cause of slow queries.
- Assuming NoSQL means no design. Schemaless does not mean thoughtless. Poor document modeling causes more pain than any rigid SQL schema ever will.
- Treating it as all-or-nothing. Many production systems use both — Postgres for orders, Redis for caching, a vector store for AI features. Polyglot persistence is normal.
Frequently Asked Questions
Is SQL or NoSQL better for beginners?
SQL is usually the better starting point. The skills transfer across nearly every relational database, the structure forces you to think clearly about your data, and the abundance of learning resources makes it easier to get unstuck. You can always add NoSQL later.
Can I use SQL and NoSQL together in one project?
Absolutely, and many teams do. A common pattern uses a relational database for core transactional data, a key-value store like Redis for caching, and a specialized store for search or analytics. This approach is called polyglot persistence.
Does NoSQL scale better than SQL?
Historically yes, because NoSQL was built for horizontal scaling across many servers. In 2026, distributed SQL databases offer comparable horizontal scale while keeping ACID transactions, so the gap is much smaller than it used to be.
Is MongoDB faster than PostgreSQL?
It depends entirely on the workload. MongoDB can be faster for reading large self-contained documents, while PostgreSQL often wins on complex queries and joins. Benchmark with your own data and access patterns rather than trusting generic claims.
Which database should a startup choose first?
For most startups, a single relational database like PostgreSQL covers structured data, flexible JSON, and even vector search in one system. Start simple, measure real bottlenecks, and introduce a second database only when a concrete need appears.
Conclusion: Making the SQL vs NoSQL Call
The SQL vs NoSQL debate has no universal winner, and anyone who tells you otherwise is selling something. SQL gives you structure, relationships, and rock-solid consistency. NoSQL gives you flexibility, varied data models, and effortless horizontal scale. In 2026, both families have absorbed each other’s strengths, which means you have more good options than ever.
When in doubt, start with a relational database like PostgreSQL — it handles the widest range of needs and rarely becomes the thing you regret. Reach for NoSQL when a specific access pattern, data shape, or scaling requirement makes it the clearly better tool. Above all, let your actual workload, not internet arguments, drive the decision.
Choose deliberately, model your data with care, and remember that the best database is the one your team understands well enough to operate confidently when that traffic spike finally arrives.