System monitoring is the cornerstone of maintaining healthy, efficient computing environments. Whether you’re managing enterprise servers or optimizing personal workstations, understanding performance metrics collection is essential for proactive system administration and troubleshooting.
Understanding System Performance Metrics
System performance metrics provide quantifiable measurements of various system resources and their utilization patterns. These metrics help identify bottlenecks, predict failures, and optimize resource allocation across different system components.

Essential Linux System Monitoring Tools
1. top and htop Commands
The top command provides real-time system statistics, while htop offers an enhanced, interactive interface with color coding and additional features.
# Basic top command
top
# Sort by memory usage
top -o %MEM
# Show specific user processes
top -u username
# htop with all cores displayed
htopSample top Output:
top - 15:45:32 up 25 days, 4:12, 3 users, load average: 0.52, 0.58, 0.65
Tasks: 298 total, 2 running, 296 sleeping, 0 stopped, 0 zombie
%Cpu(s): 8.5 us, 2.3 sy, 0.0 ni, 88.7 id, 0.3 wa, 0.0 hi, 0.2 si, 0.0 st
MiB Mem : 16048.5 total, 2156.8 free, 8945.2 used, 4946.5 buff/cache
MiB Swap: 2048.0 total, 1987.3 free, 60.7 used. 6398.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2847 mysql 20 0 1819540 674532 28096 S 12.9 4.1 485:32.18 mysqld
1234 apache 20 0 256789 89234 12456 S 8.3 0.5 45:23.67 httpd2. vmstat – Virtual Memory Statistics
The vmstat command reports information about processes, memory, paging, block IO, traps, and CPU activity.
# Display current statistics
vmstat
# Update every 2 seconds, 5 times
vmstat 2 5
# Display memory statistics in MB
vmstat -S M
# Show disk statistics
vmstat -dSample vmstat Output:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 60 2156832 487234 4946512 0 0 8 15 156 298 9 2 88 1 0
1 0 60 2154567 487245 4947821 0 0 0 12 167 312 8 2 89 1 0
3. iostat – Input/Output Statistics
Part of the sysstat package, iostat monitors system input/output device loading by observing the time devices are active.
# Basic I/O statistics
iostat
# Update every 3 seconds
iostat 3
# Show extended statistics
iostat -x
# Display specific device statistics
iostat -x sda 2 5Sample iostat Output:
Linux 5.4.0-74-generic (server01) 08/28/2025 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
8.45 0.02 2.34 0.87 0.00 88.32
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s
sda 8.45 12.34 156.78 234.56 0.12 2.34
sdb 2.34 5.67 45.23 89.45 0.05 1.124. sar – System Activity Reporter
The sar command collects, reports, and saves system activity information, making it invaluable for historical analysis.
# CPU utilization every 2 seconds, 5 times
sar -u 2 5
# Memory utilization
sar -r 2 5
# Network statistics
sar -n DEV 2 5
# Disk I/O statistics
sar -d 2 5
# Load average and queue length
sar -q 2 5Windows System Monitoring Tools
1. Performance Monitor (perfmon)
Windows Performance Monitor provides comprehensive system performance data through counters, logs, and alerts.
# Open Performance Monitor
perfmon
# Command-line performance data
typeperf "\Processor(_Total)\% Processor Time" -sc 10
# Memory usage counter
typeperf "\Memory\Available MBytes" -sc 5
# Disk performance
typeperf "\PhysicalDisk(_Total)\Disk Reads/sec" -sc 102. Resource Monitor (resmon)
Resource Monitor provides detailed real-time information about system resource usage including CPU, memory, disk, and network.
# Open Resource Monitor
resmon
# Command-line equivalent using wmic
wmic process get ProcessId,Name,WorkingSetSize,PageFileUsage
# CPU information
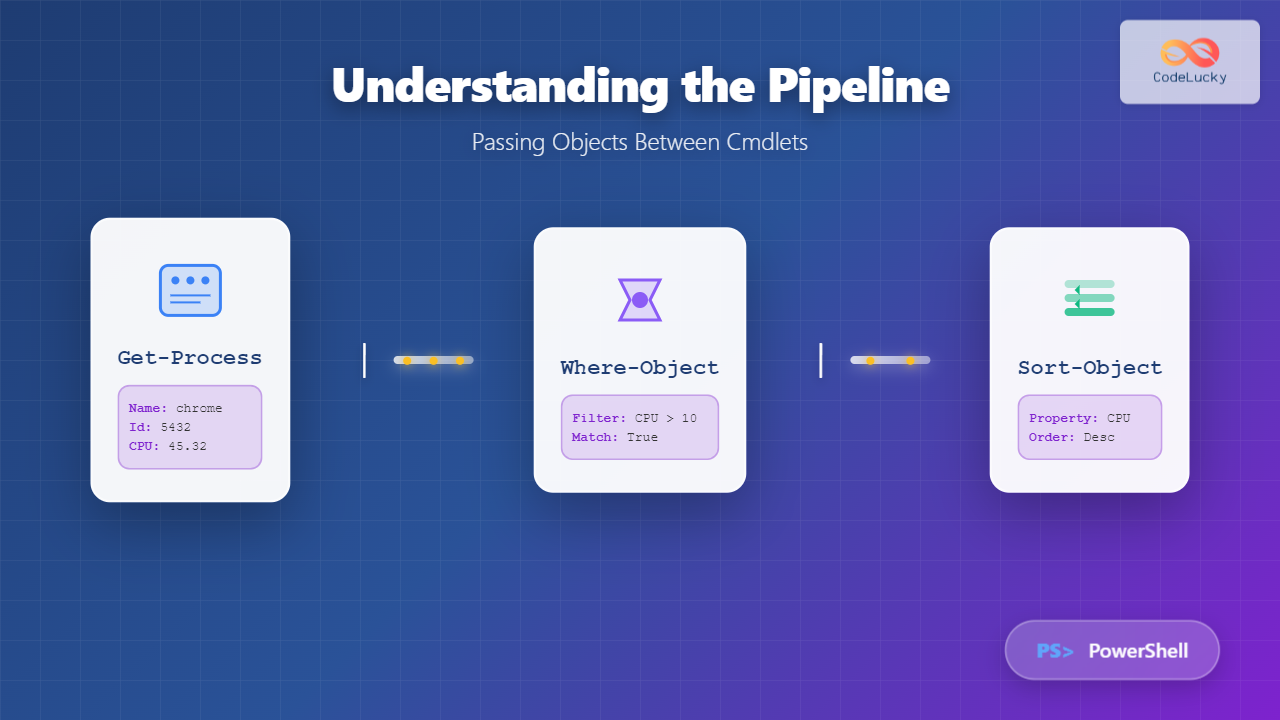
wmic cpu get LoadPercentage /every:13. PowerShell System Monitoring
PowerShell offers powerful cmdlets for system monitoring and performance data collection.
# Get system information
Get-ComputerInfo
# CPU usage
Get-Counter "\Processor(_Total)\% Processor Time" -SampleInterval 1 -MaxSamples 5
# Memory information
Get-Counter "\Memory\Available MBytes"
# Disk performance
Get-Counter "\PhysicalDisk(_Total)\Disk Reads/sec"
# Network adapter statistics
Get-NetAdapterStatisticsAdvanced Monitoring Solutions
1. Nagios Core
Nagios provides comprehensive monitoring of systems, networks, and infrastructure with alerting capabilities.
# Sample Nagios service check configuration
define service {
use generic-service
host_name webserver01
service_description CPU Load
check_command check_nrpe!check_load
normal_check_interval 5
retry_check_interval 1
}2. Zabbix Agent Configuration
Zabbix offers enterprise-level monitoring with auto-discovery and distributed monitoring capabilities.
# Zabbix agent configuration sample
Server=192.168.1.100
ServerActive=192.168.1.100
Hostname=webserver01
# Custom user parameters
UserParameter=mysql.ping,mysqladmin ping | grep alive | wc -l
UserParameter=mysql.uptime,mysqladmin status | cut -f2 -d":" | cut -f1 -d"T"
Container and Cloud Monitoring
1. Docker Container Monitoring
Monitoring containerized applications requires specialized tools and approaches for resource tracking.
# Docker container statistics
docker stats
# Specific container monitoring
docker stats container_name
# Container resource usage with format
docker stats --format "table {{.Container}}\t{{.CPUPerc}}\t{{.MemUsage}}"
# Docker system events
docker system events
# Container logs monitoring
docker logs -f container_name2. Kubernetes Monitoring
Kubernetes environments require comprehensive monitoring of pods, nodes, and cluster resources.
# Node resource usage
kubectl top nodes
# Pod resource usage
kubectl top pods
# Cluster resource usage by namespace
kubectl top pods --all-namespaces
# Describe node resources
kubectl describe node node-name
# Get cluster events
kubectl get events --sort-by='.lastTimestamp'Log Analysis and Monitoring
1. System Log Monitoring
Log files provide crucial information about system health, errors, and security events.
# Monitor system logs in real-time
tail -f /var/log/syslog
# Search for specific patterns
grep "error" /var/log/syslog | tail -20
# Monitor multiple log files
multitail /var/log/syslog /var/log/auth.log
# Analyze log file sizes
du -sh /var/log/*
# Count error occurrences
grep -c "ERROR" /var/log/application.log2. Centralized Logging with ELK Stack
Elasticsearch, Logstash, and Kibana provide powerful centralized logging and analysis capabilities.
# Logstash configuration sample
input {
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}Performance Tuning Based on Metrics

Automated Monitoring Scripts
System Health Check Script
#!/bin/bash
# System Health Monitoring Script
DATE=$(date)
HOSTNAME=$(hostname)
echo "=== System Health Report for $HOSTNAME - $DATE ==="
# CPU Usage
echo "CPU Usage:"
top -bn1 | grep "Cpu(s)" | awk '{print $2}' | cut -d'%' -f1
# Memory Usage
echo "Memory Usage:"
free -m | awk 'NR==2{printf "%.2f%%\n", $3*100/$2}'
# Disk Usage
echo "Disk Usage:"
df -h | awk '$5 > 80 {print $1 " " $5}'
# Load Average
echo "Load Average:"
uptime | awk -F'load average:' '{ print $2 }'
# Network Connections
echo "Active Network Connections:"
netstat -tuln | wc -l
# System Uptime
echo "System Uptime:"
uptime | awk '{print $3,$4}' | sed 's/,//'Best Practices for System Monitoring
1. Monitoring Strategy
- Baseline Establishment: Create performance baselines during normal operations
- Threshold Setting: Define appropriate alert thresholds based on historical data
- Proactive Monitoring: Monitor trends rather than just current values
- Comprehensive Coverage: Monitor all critical system components
2. Data Retention and Analysis
- Historical Data: Maintain sufficient historical data for trend analysis
- Data Granularity: Balance detail level with storage requirements
- Regular Reviews: Conduct periodic performance reviews
- Capacity Planning: Use metrics for future resource planning

Conclusion
Effective system monitoring is essential for maintaining optimal performance, preventing downtime, and ensuring system reliability. By implementing comprehensive monitoring strategies using the tools and techniques outlined in this guide, system administrators can proactively manage their infrastructure and respond quickly to performance issues.
The combination of real-time monitoring, historical analysis, and automated alerting provides a robust foundation for system management. Whether using built-in system tools or enterprise monitoring solutions, the key is to establish consistent monitoring practices that align with your organization’s requirements and scale with your infrastructure growth.
Remember that monitoring is not a one-time setup but an ongoing process that requires regular review and optimization. Stay current with new monitoring technologies and continuously refine your monitoring strategy to match evolving system demands and business requirements.