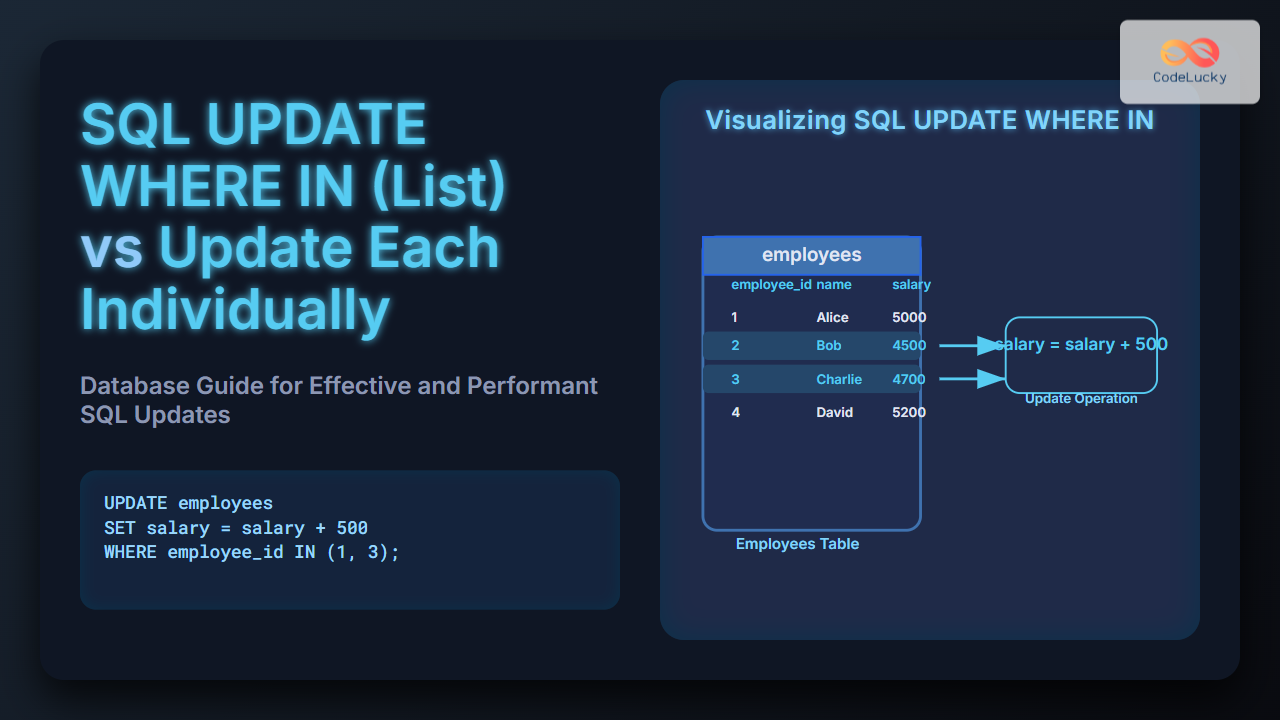
In the world of database management, maintaining data integrity is paramount. SQL constraints are the guardians of this integrity, ensuring that the data in your tables adheres to specific rules and conditions. These powerful tools not only prevent invalid data from entering your database but also help maintain consistency across related tables.
Understanding SQL Constraints
SQL constraints are rules that you define on table columns to enforce data integrity. They act as a safety net, catching and preventing errors before they can compromise your data's quality and reliability.
🔑 Key Point: Constraints are like bouncers at a club, only allowing data that meets certain criteria to enter your database.
There are several types of constraints in SQL, each serving a unique purpose:
- NOT NULL Constraint
- UNIQUE Constraint
- PRIMARY KEY Constraint
- FOREIGN KEY Constraint
- CHECK Constraint
- DEFAULT Constraint
Let's dive deep into each of these constraints, exploring their functionality with practical examples.
NOT NULL Constraint
The NOT NULL constraint ensures that a column cannot have a NULL value. This is particularly useful when you have columns that should always contain data.
Example: Creating a Table with NOT NULL Constraint
Let's create a table for storing employee information:
CREATE TABLE employees (
employee_id INT NOT NULL,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100),
hire_date DATE NOT NULL
);
In this example, we've made employee_id, first_name, last_name, and hire_date NOT NULL, as these are essential pieces of information that should always be provided.
Now, let's try to insert some data:
-- This will work
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date)
VALUES (1, 'John', 'Doe', '[email protected]', '2023-06-01');
-- This will fail due to NULL in a NOT NULL column
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date)
VALUES (2, 'Jane', NULL, '[email protected]', '2023-06-02');
The second INSERT statement will fail because we're trying to insert a NULL value into the last_name column, which is defined as NOT NULL.
🚫 Error Message: "Column 'last_name' cannot be null"
UNIQUE Constraint
The UNIQUE constraint ensures that all values in a column (or a combination of columns) are different. This is useful for columns like email addresses or usernames where you want to prevent duplicates.
Example: Adding a UNIQUE Constraint
Let's modify our employees table to make the email address unique:
ALTER TABLE employees
ADD CONSTRAINT unique_email UNIQUE (email);
Now, let's try to insert some data:
-- This will work
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date)
VALUES (3, 'Alice', 'Johnson', '[email protected]', '2023-06-03');
-- This will fail due to duplicate email
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date)
VALUES (4, 'Bob', 'Williams', '[email protected]', '2023-06-04');
The second INSERT statement will fail because we're trying to insert a duplicate email address.
🚫 Error Message: "Duplicate entry '[email protected]' for key 'unique_email'"
PRIMARY KEY Constraint
The PRIMARY KEY constraint uniquely identifies each record in a table. It must contain UNIQUE values and cannot contain NULL values. A table can have only one primary key, which may consist of single or multiple columns.
Example: Creating a Table with a PRIMARY KEY
Let's create a new table for departments:
CREATE TABLE departments (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(100) NOT NULL,
location VARCHAR(100)
);
Now, let's insert some data:
-- These will work
INSERT INTO departments (dept_id, dept_name, location)
VALUES (1, 'Human Resources', 'New York');
INSERT INTO departments (dept_id, dept_name, location)
VALUES (2, 'Marketing', 'Los Angeles');
-- This will fail due to duplicate PRIMARY KEY
INSERT INTO departments (dept_id, dept_name, location)
VALUES (1, 'Finance', 'Chicago');
The third INSERT statement will fail because we're trying to insert a duplicate dept_id, which is our PRIMARY KEY.
🚫 Error Message: "Duplicate entry '1' for key 'PRIMARY'"
FOREIGN KEY Constraint
The FOREIGN KEY constraint is used to prevent actions that would destroy links between tables. It creates a link between two tables, where the FOREIGN KEY in one table refers to the PRIMARY KEY in another table.
Example: Adding a FOREIGN KEY Constraint
Let's modify our employees table to include a reference to the departments table:
ALTER TABLE employees
ADD COLUMN dept_id INT,
ADD CONSTRAINT fk_dept
FOREIGN KEY (dept_id) REFERENCES departments(dept_id);
Now, let's try to insert and update some data:
-- This will work
UPDATE employees SET dept_id = 1 WHERE employee_id = 1;
-- This will fail due to non-existent department
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date, dept_id)
VALUES (5, 'Charlie', 'Brown', '[email protected]', '2023-06-05', 100);
The INSERT statement will fail because we're trying to assign the employee to a department (100) that doesn't exist in the departments table.
🚫 Error Message: "Cannot add or update a child row: a foreign key constraint fails"
CHECK Constraint
The CHECK constraint ensures that all values in a column satisfy certain conditions. It allows you to specify a Boolean expression that must evaluate to TRUE for each row in the table.
Example: Adding a CHECK Constraint
Let's add a CHECK constraint to ensure that the hire date is not in the future:
ALTER TABLE employees
ADD CONSTRAINT check_hire_date
CHECK (hire_date <= CURRENT_DATE);
Now, let's try to insert some data:
-- This will work
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date)
VALUES (6, 'David', 'Miller', '[email protected]', '2023-06-06');
-- This will fail due to future hire date
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date)
VALUES (7, 'Eva', 'Garcia', '[email protected]', '2024-01-01');
The second INSERT statement will fail because we're trying to insert a hire date that's in the future.
🚫 Error Message: "Check constraint 'check_hire_date' is violated"
DEFAULT Constraint
The DEFAULT constraint is used to provide a default value for a column when no value is specified during an INSERT operation.
Example: Adding a DEFAULT Constraint
Let's add a DEFAULT constraint to set a default location for departments:
ALTER TABLE departments
ALTER COLUMN location SET DEFAULT 'Head Office';
Now, let's insert some data:
-- This will use the default location
INSERT INTO departments (dept_id, dept_name)
VALUES (3, 'IT');
-- This will override the default
INSERT INTO departments (dept_id, dept_name, location)
VALUES (4, 'Sales', 'San Francisco');
Let's check the results:
SELECT * FROM departments;
| dept_id | dept_name | location |
|---|---|---|
| 1 | Human Resources | New York |
| 2 | Marketing | Los Angeles |
| 3 | IT | Head Office |
| 4 | Sales | San Francisco |
As you can see, the IT department got the default location of 'Head Office', while the Sales department has its specified location of 'San Francisco'.
Combining Constraints
In real-world scenarios, you'll often use multiple constraints together to enforce complex rules on your data. Let's create a new table that combines several constraints:
CREATE TABLE projects (
project_id INT PRIMARY KEY,
project_name VARCHAR(100) NOT NULL UNIQUE,
start_date DATE NOT NULL,
end_date DATE,
budget DECIMAL(10,2) NOT NULL CHECK (budget > 0),
dept_id INT NOT NULL,
FOREIGN KEY (dept_id) REFERENCES departments(dept_id),
CHECK (end_date IS NULL OR end_date > start_date)
);
This projects table includes:
- A PRIMARY KEY constraint on
project_id - NOT NULL constraints on several columns
- A UNIQUE constraint on
project_name - A CHECK constraint to ensure the budget is positive
- A FOREIGN KEY constraint linking to the
departmentstable - A complex CHECK constraint to ensure the end date is after the start date (if specified)
Let's try inserting some data:
-- This will work
INSERT INTO projects (project_id, project_name, start_date, end_date, budget, dept_id)
VALUES (1, 'Website Redesign', '2023-07-01', '2023-12-31', 50000.00, 2);
-- This will fail due to duplicate project name
INSERT INTO projects (project_id, project_name, start_date, end_date, budget, dept_id)
VALUES (2, 'Website Redesign', '2023-08-01', '2023-11-30', 30000.00, 2);
-- This will fail due to negative budget
INSERT INTO projects (project_id, project_name, start_date, end_date, budget, dept_id)
VALUES (3, 'Cost Cutting Initiative', '2023-09-01', '2024-03-31', -10000.00, 1);
-- This will fail due to end date before start date
INSERT INTO projects (project_id, project_name, start_date, end_date, budget, dept_id)
VALUES (4, 'Employee Training Program', '2023-10-01', '2023-09-30', 20000.00, 1);
Only the first INSERT statement will succeed. The others will fail due to various constraint violations.
Conclusion
SQL constraints are powerful tools for maintaining data integrity in your database. By implementing these rules, you can prevent many common data errors and ensure that your database remains consistent and reliable.
🔑 Key Takeaways:
- NOT NULL prevents empty values in important fields
- UNIQUE ensures no duplicates in specified columns
- PRIMARY KEY uniquely identifies each record
- FOREIGN KEY maintains referential integrity between tables
- CHECK allows for custom validation rules
- DEFAULT provides fallback values for columns
Remember, while constraints can seem restrictive, they're actually liberating. They free you from worrying about bad data entering your system, allowing you to focus on using your data rather than constantly cleaning and validating it.
By mastering SQL constraints, you're taking a significant step towards becoming a proficient database developer. Keep practicing, and soon you'll be designing robust database schemas that stand the test of time and data volume.
Related Posts

SQL CHECK Constraint: Validating Data in Tables
In the world of database management, ensuring data integrity is paramount. One powerful tool in the SQL arsenal for maintaining...
MySQL Constraints: Ensuring Data Integrity
Data is the lifeblood of any application, and ensuring its accuracy and consistency is paramount. MySQL constraints are the gatekeepers...

MySQL Check Constraint: Ensuring Data Integrity with Validation Rules
Data is the lifeblood of any application, and ensuring its accuracy is paramount. That's where MySQL CHECK constraints come in....

SQL UNIQUE Constraint: Preventing Duplicate Values
In the world of database management, ensuring data integrity is paramount. One of the key aspects of maintaining data integrity...

MySQL Unique: Ensuring Data Integrity with Unique Constraints
In the world of databases, ensuring data integrity is paramount. One crucial tool for this is the UNIQUE constraint in...

SQL NOT NULL Constraint: Ensuring Required Data
In the world of database management, data integrity is paramount. One of the fundamental ways to maintain this integrity is...

MySQL Foreign Key: Ensuring Data Integrity
Foreign keys are the unsung heroes of database design. They are a crucial part of maintaining referential integrity, ensuring that...

SQL FOREIGN KEY: Linking Tables in Databases
In the world of relational databases, data is often spread across multiple tables. While this approach helps maintain data integrity...

SQL DEFAULT Constraint: Setting Default Values
In the world of database management, ensuring data integrity and consistency is paramount. One powerful tool in our SQL arsenal...

MySQL Not Null: Ensuring Data Integrity and Preventing Errors
In the realm of databases, maintaining data integrity is paramount. One of the most effective tools for achieving this in...

SQL Table Locking: Managing Concurrent Access
In the world of database management, ensuring data integrity while allowing multiple users to access and modify data simultaneously is...

SQL PRIMARY KEY: Defining Unique Identifiers in Tables
In the world of relational databases, the concept of a PRIMARY KEY is fundamental to maintaining data integrity and establishing...