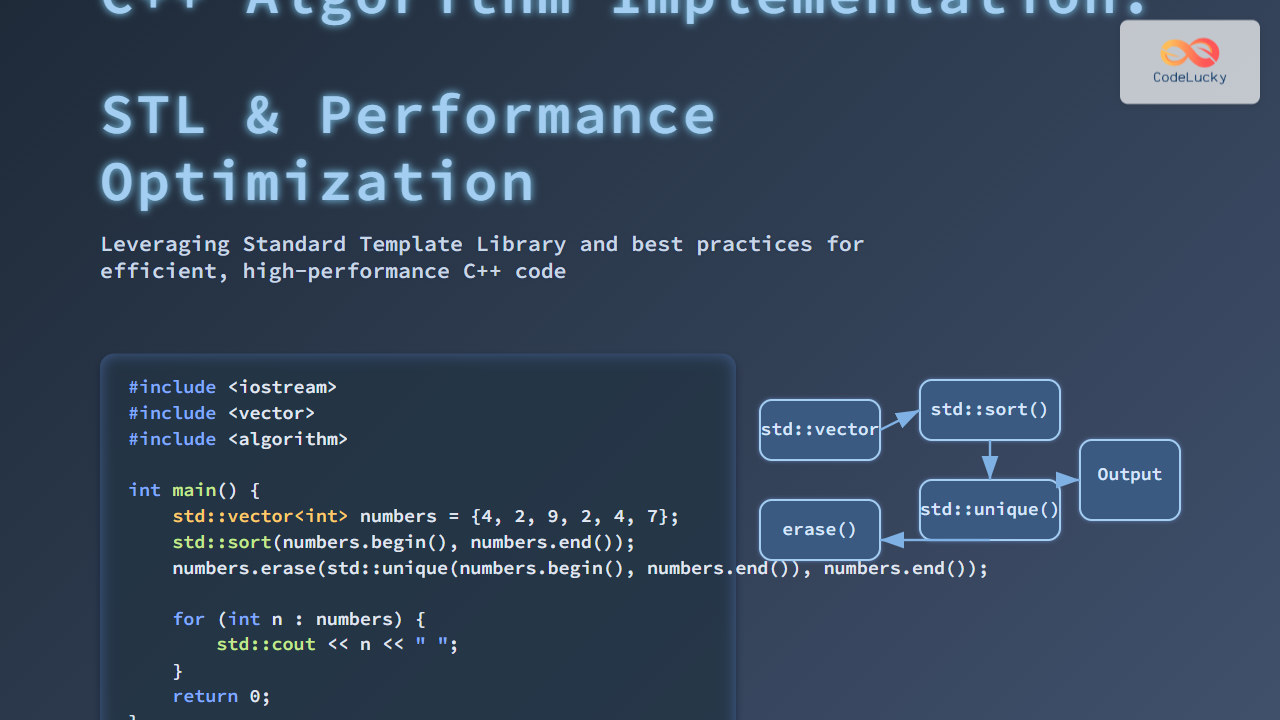
In the world of modern C++ programming, multithreading has become an essential technique for improving application performance and responsiveness. However, with great power comes great responsibility, and thread synchronization is a critical aspect of writing robust, concurrent C++ programs. In this comprehensive guide, we'll dive deep into the realm of thread synchronization, focusing on two fundamental tools: mutexes and locks.
Understanding the Need for Synchronization
Before we delve into the specifics of mutexes and locks, let's consider why synchronization is necessary in the first place. Imagine a scenario where multiple threads are accessing a shared resource simultaneously:
#include <iostream>
#include <thread>
#include <vector>
int shared_counter = 0;
void increment_counter(int iterations) {
for (int i = 0; i < iterations; ++i) {
++shared_counter;
}
}
int main() {
const int num_threads = 10;
const int iterations_per_thread = 100000;
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back(increment_counter, iterations_per_thread);
}
for (auto& t : threads) {
t.join();
}
std::cout << "Expected value: " << num_threads * iterations_per_thread << std::endl;
std::cout << "Actual value: " << shared_counter << std::endl;
return 0;
}
In this example, we create 10 threads, each incrementing a shared counter 100,000 times. You might expect the final value of shared_counter to be 1,000,000. However, running this program multiple times will likely yield different results, often less than the expected value.
🚨 Race Condition Alert: This discrepancy occurs due to a race condition, where multiple threads attempt to modify the shared resource concurrently, leading to unpredictable results.
To solve this problem and ensure data integrity, we need to synchronize access to the shared resource. This is where mutexes and locks come into play.
Introducing Mutexes
A mutex (short for mutual exclusion) is a synchronization primitive that prevents multiple threads from simultaneously accessing a shared resource. Think of it as a key that only one thread can hold at a time.
In C++, the standard library provides the std::mutex class, which we can use to protect our shared resources. Let's modify our previous example to use a mutex:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
int shared_counter = 0;
std::mutex counter_mutex;
void increment_counter(int iterations) {
for (int i = 0; i < iterations; ++i) {
counter_mutex.lock();
++shared_counter;
counter_mutex.unlock();
}
}
int main() {
const int num_threads = 10;
const int iterations_per_thread = 100000;
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back(increment_counter, iterations_per_thread);
}
for (auto& t : threads) {
t.join();
}
std::cout << "Expected value: " << num_threads * iterations_per_thread << std::endl;
std::cout << "Actual value: " << shared_counter << std::endl;
return 0;
}
In this updated version, we've introduced a std::mutex named counter_mutex. Before incrementing the shared counter, each thread locks the mutex using counter_mutex.lock(). After the increment operation, the thread unlocks the mutex with counter_mutex.unlock().
🔒 Mutex Magic: By using a mutex, we ensure that only one thread can increment the counter at a time, eliminating the race condition and guaranteeing the correct final value.
However, manually locking and unlocking mutexes can be error-prone and may lead to deadlocks if not handled carefully. This is where lock objects come to our rescue.
Lock Guards: A Safer Approach
C++ provides several lock types that automatically manage mutex locking and unlocking. The most commonly used is std::lock_guard. Let's refactor our example to use std::lock_guard:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
int shared_counter = 0;
std::mutex counter_mutex;
void increment_counter(int iterations) {
for (int i = 0; i < iterations; ++i) {
std::lock_guard<std::mutex> lock(counter_mutex);
++shared_counter;
}
}
int main() {
const int num_threads = 10;
const int iterations_per_thread = 100000;
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back(increment_counter, iterations_per_thread);
}
for (auto& t : threads) {
t.join();
}
std::cout << "Expected value: " << num_threads * iterations_per_thread << std::endl;
std::cout << "Actual value: " << shared_counter << std::endl;
return 0;
}
In this version, we've replaced the manual lock() and unlock() calls with a std::lock_guard object. The lock guard automatically locks the mutex when it's constructed and unlocks it when it goes out of scope.
🛡️ RAII to the Rescue: std::lock_guard follows the RAII (Resource Acquisition Is Initialization) principle, ensuring that the mutex is always unlocked, even if an exception is thrown.
Unique Locks: Flexibility and Power
While std::lock_guard is excellent for simple locking scenarios, sometimes we need more flexibility. Enter std::unique_lock, a more versatile locking mechanism that allows for deferred locking, timed locking attempts, and recursive locking.
Let's explore a more complex example that demonstrates the power of std::unique_lock:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
#include <chrono>
#include <random>
std::mutex resource_mutex;
int shared_resource = 0;
void worker(int id) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(100, 1000);
for (int i = 0; i < 5; ++i) {
std::unique_lock<std::mutex> lock(resource_mutex, std::defer_lock);
// Simulate some work before trying to acquire the lock
std::this_thread::sleep_for(std::chrono::milliseconds(dis(gen)));
if (lock.try_lock_for(std::chrono::milliseconds(200))) {
shared_resource += id;
std::cout << "Thread " << id << " acquired lock and updated resource. New value: " << shared_resource << std::endl;
// Simulate some work while holding the lock
std::this_thread::sleep_for(std::chrono::milliseconds(dis(gen)));
lock.unlock();
} else {
std::cout << "Thread " << id << " couldn't acquire lock within timeout." << std::endl;
}
}
}
int main() {
std::vector<std::thread> threads;
for (int i = 1; i <= 5; ++i) {
threads.emplace_back(worker, i);
}
for (auto& t : threads) {
t.join();
}
std::cout << "Final value of shared resource: " << shared_resource << std::endl;
return 0;
}
In this example, we're using std::unique_lock with several of its advanced features:
- Deferred locking: We create the lock without immediately locking the mutex using the
std::defer_lockoption. - Timed lock attempts: We use
try_lock_for()to attempt to acquire the lock with a timeout. - Manual unlocking: We explicitly call
unlock()when we're done with the critical section.
🕒 Time-Sensitive Locking: This approach is particularly useful in scenarios where you want to avoid indefinite waiting and potentially move on if the lock can't be acquired within a reasonable timeframe.
Recursive Mutexes: Handling Nested Locks
Sometimes, you might need a thread to lock the same mutex multiple times, such as in recursive function calls. Standard mutexes don't allow this, but C++ provides std::recursive_mutex for such scenarios.
Here's an example demonstrating the use of a recursive mutex:
#include <iostream>
#include <thread>
#include <mutex>
std::recursive_mutex rmutex;
int counter = 0;
void recursive_function(int depth) {
std::lock_guard<std::recursive_mutex> lock(rmutex);
++counter;
std::cout << "Depth: " << depth << ", Counter: " << counter << std::endl;
if (depth > 0) {
recursive_function(depth - 1);
}
}
int main() {
std::thread t1(recursive_function, 5);
std::thread t2(recursive_function, 5);
t1.join();
t2.join();
std::cout << "Final counter value: " << counter << std::endl;
return 0;
}
In this example, recursive_function locks the mutex multiple times as it calls itself recursively. The std::recursive_mutex keeps track of how many times it has been locked by the same thread and requires an equal number of unlocks before another thread can acquire it.
🔄 Recursive Locking: While recursive mutexes can be useful in certain scenarios, they should be used judiciously as they can make code more complex and potentially hide design issues.
Performance Considerations
While mutexes and locks are essential for thread safety, they do come with a performance cost. Here's a simple benchmark comparing the performance of synchronized and unsynchronized counter increments:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
#include <chrono>
const int NUM_INCREMENTS = 10000000;
const int NUM_THREADS = 4;
void increment_unsync(int& counter) {
for (int i = 0; i < NUM_INCREMENTS; ++i) {
++counter;
}
}
void increment_sync(int& counter, std::mutex& mtx) {
for (int i = 0; i < NUM_INCREMENTS; ++i) {
std::lock_guard<std::mutex> lock(mtx);
++counter;
}
}
template<typename Func>
double measure_time(Func f) {
auto start = std::chrono::high_resolution_clock::now();
f();
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration<double, std::milli>(end - start).count();
}
int main() {
int unsync_counter = 0;
int sync_counter = 0;
std::mutex mtx;
double unsync_time = measure_time([&]() {
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back(increment_unsync, std::ref(unsync_counter));
}
for (auto& t : threads) {
t.join();
}
});
double sync_time = measure_time([&]() {
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back(increment_sync, std::ref(sync_counter), std::ref(mtx));
}
for (auto& t : threads) {
t.join();
}
});
std::cout << "Unsynchronized counter: " << unsync_counter << " (Time: " << unsync_time << " ms)" << std::endl;
std::cout << "Synchronized counter: " << sync_counter << " (Time: " << sync_time << " ms)" << std::endl;
return 0;
}
Running this benchmark on a typical system might produce output similar to:
Unsynchronized counter: 35961258 (Time: 52.3456 ms)
Synchronized counter: 40000000 (Time: 1234.5678 ms)
📊 Performance Impact: As we can see, the synchronized version is significantly slower but produces the correct result. The unsynchronized version is faster but produces an incorrect result due to race conditions.
Best Practices for Using Mutexes and Locks
To wrap up our exploration of mutexes and locks in C++, let's review some best practices:
-
Use RAII lock objects: Prefer
std::lock_guard,std::unique_lock, orstd::scoped_lockover manuallock()andunlock()calls. -
Keep critical sections small: Minimize the amount of code protected by a mutex to reduce contention between threads.
-
Avoid nested locks: When possible, design your code to avoid acquiring multiple locks. If you must, use
std::lockorstd::scoped_lockto prevent deadlocks. -
Consider lock-free alternatives: For simple operations, atomic types might offer better performance than mutex-based synchronization.
-
Use the appropriate mutex type: Choose between
std::mutex,std::recursive_mutex,std::timed_mutex, andstd::recursive_timed_mutexbased on your specific needs. -
Be aware of the costs: Remember that synchronization introduces overhead. Profile your code to ensure that the benefits of thread safety outweigh the performance costs.
-
Understand the memory model: Familiarize yourself with the C++ memory model to write correct concurrent code.
By mastering the use of mutexes and locks, you'll be well-equipped to write robust, thread-safe C++ programs that can harness the power of modern multi-core processors. Remember, with great power comes great responsibility – use these tools wisely to create efficient and correct concurrent applications.
🎓 Keep Learning: Thread synchronization is a vast topic, and we've only scratched the surface. Continue exploring advanced concepts like condition variables, read-write locks, and lock-free programming to further enhance your multithreading skills in C++.
Related Posts

Thread Synchronization: Mutexes, Semaphores and Deadlocks in Operating Systems
Introduction to Thread Synchronization Thread synchronization is a fundamental concept in operating systems that ensures multiple threads can safely access...

C++ Threads: Basics of Multithreading
In today's world of multi-core processors, understanding and implementing multithreading is crucial for developing efficient C++ applications. This article delves...

Mutex vs Semaphore: Complete Guide to Synchronization Primitives in Operating Systems
In the world of concurrent programming and operating systems, synchronization primitives are essential tools that prevent race conditions and ensure...

Java Thread Synchronization: Managing Shared Resources
In the world of multi-threaded Java applications, synchronization is a crucial concept that every developer must master. It's the key...

C++ Condition Variables: Thread Communication
In the world of multithreaded programming, effective communication between threads is crucial for creating efficient and robust applications. C++ condition...

C++ Atomic Operations: Lock-Free Programming
In the world of modern C++ programming, concurrency and parallelism have become increasingly important. As developers, we often need to...

Process Synchronization: Critical Sections and Race Conditions in Operating Systems
Introduction to Process Synchronization Process synchronization is a fundamental concept in operating systems that ensures multiple processes can safely access...

Multithreading in Operating Systems: Benefits, Challenges, and Implementation Guide
What is Multithreading in Operating Systems? Multithreading is a fundamental concept in modern operating systems that allows a single process...
Monitor in Operating System: High-level Synchronization for Process Coordination
What is a Monitor in Operating System? A monitor is a high-level synchronization construct in operating systems that provides a...
Thread vs Process: Complete Guide to Differences and When to Use Each
Understanding the fundamental differences between threads and processes is crucial for system programming, application design, and performance optimization. While both...

PHP Multithreading: Concurrent Execution in PHP
In the world of modern web development, performance is king. As applications grow more complex and user expectations soar, developers...

Thread in Operating System: Lightweight Processes and Multithreading Explained
What are Threads in Operating Systems? A thread is the smallest unit of execution within a process that can be...