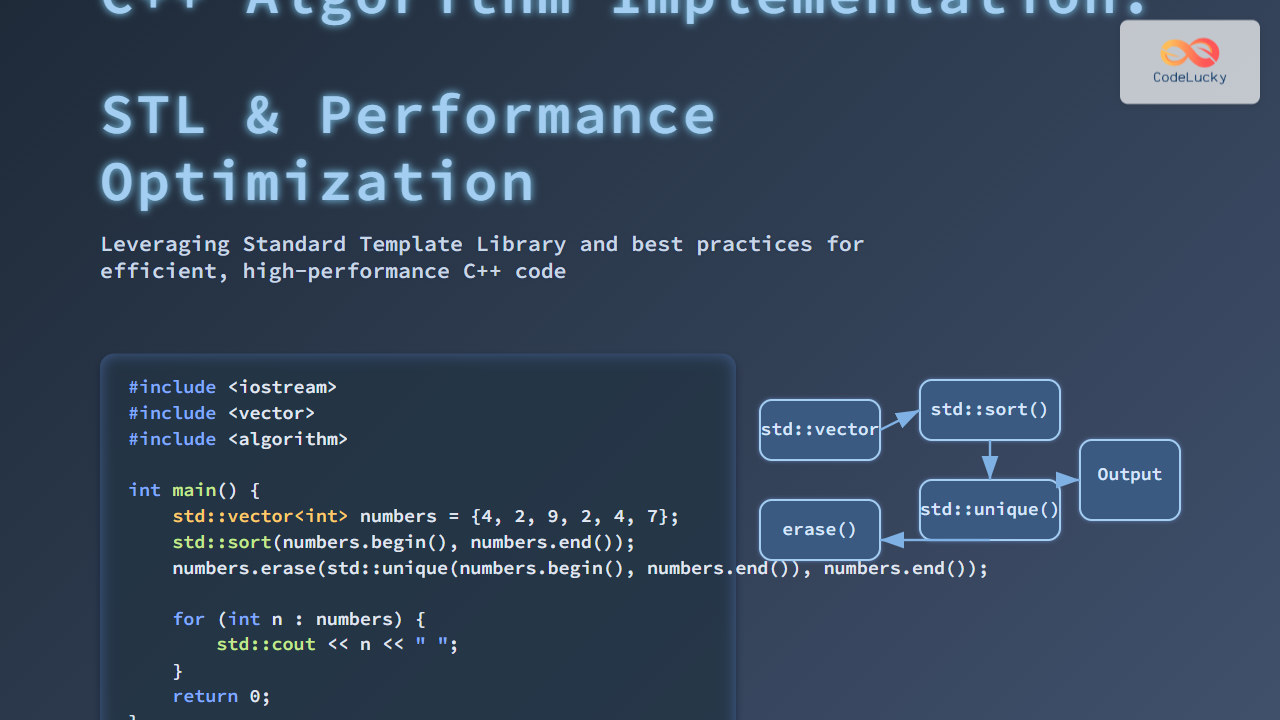
C++ sets are powerful containers that store unique elements in a specific order. They're particularly useful when you need to maintain a collection of distinct items and perform various set operations. In this comprehensive guide, we'll explore the essential set methods and operations in C++, providing you with practical examples and in-depth explanations.
Understanding C++ Sets
Before we dive into set operations, let's briefly review what sets are in C++:
- Sets are associative containers that store unique elements
- Elements in a set are always sorted
- Sets are typically implemented as binary search trees
- The
<set>header provides the set container
🔑 Key Point: Sets automatically maintain their elements in sorted order, which makes certain operations very efficient.
Basic Set Operations
Let's start with some fundamental set operations:
1. Inserting Elements
To add elements to a set, we use the insert() method:
#include <iostream>
#include <set>
int main() {
std::set<int> numbers;
numbers.insert(5);
numbers.insert(3);
numbers.insert(7);
numbers.insert(5); // Duplicate, won't be inserted
for (int num : numbers) {
std::cout << num << " ";
}
return 0;
}
Output:
3 5 7
🔍 Note: The duplicate value (5) is not inserted, as sets only store unique elements.
2. Removing Elements
To remove elements from a set, we use the erase() method:
#include <iostream>
#include <set>
int main() {
std::set<char> letters {'a', 'b', 'c', 'd', 'e'};
letters.erase('c');
letters.erase('f'); // No effect, 'f' is not in the set
for (char letter : letters) {
std::cout << letter << " ";
}
return 0;
}
Output:
a b d e
💡 Tip: The erase() method is safe to use even if the element doesn't exist in the set.
3. Checking for Element Existence
To check if an element exists in a set, we can use the count() method:
#include <iostream>
#include <set>
int main() {
std::set<std::string> fruits {"apple", "banana", "cherry"};
std::cout << "Is 'banana' in the set? " << (fruits.count("banana") > 0 ? "Yes" : "No") << std::endl;
std::cout << "Is 'grape' in the set? " << (fruits.count("grape") > 0 ? "Yes" : "No") << std::endl;
return 0;
}
Output:
Is 'banana' in the set? Yes
Is 'grape' in the set? No
🔑 Key Point: The count() method returns 1 if the element is in the set, and 0 otherwise.
Advanced Set Operations
Now let's explore some more advanced set operations that are crucial for working with multiple sets:
1. Set Union
The set union operation combines two sets, keeping only unique elements. We can use the set_union() algorithm from the <algorithm> header:
#include <iostream>
#include <set>
#include <algorithm>
#include <iterator>
int main() {
std::set<int> set1 {1, 3, 5, 7, 9};
std::set<int> set2 {2, 3, 5, 7, 11};
std::set<int> result;
std::set_union(set1.begin(), set1.end(),
set2.begin(), set2.end(),
std::inserter(result, result.begin()));
std::cout << "Union of set1 and set2: ";
for (int num : result) {
std::cout << num << " ";
}
return 0;
}
Output:
Union of set1 and set2: 1 2 3 5 7 9 11
🔍 Note: The set_union() algorithm requires sorted ranges, which is guaranteed by the set container.
2. Set Intersection
The set intersection operation finds common elements between two sets. We use the set_intersection() algorithm:
#include <iostream>
#include <set>
#include <algorithm>
#include <iterator>
int main() {
std::set<char> set1 {'a', 'b', 'c', 'd', 'e'};
std::set<char> set2 {'c', 'd', 'e', 'f', 'g'};
std::set<char> result;
std::set_intersection(set1.begin(), set1.end(),
set2.begin(), set2.end(),
std::inserter(result, result.begin()));
std::cout << "Intersection of set1 and set2: ";
for (char c : result) {
std::cout << c << " ";
}
return 0;
}
Output:
Intersection of set1 and set2: c d e
💡 Tip: The set_intersection() algorithm is particularly useful when you need to find common elements efficiently.
3. Set Difference
The set difference operation finds elements that are in one set but not in another. We use the set_difference() algorithm:
#include <iostream>
#include <set>
#include <algorithm>
#include <iterator>
int main() {
std::set<std::string> fruits1 {"apple", "banana", "cherry", "date"};
std::set<std::string> fruits2 {"banana", "date", "elderberry"};
std::set<std::string> result;
std::set_difference(fruits1.begin(), fruits1.end(),
fruits2.begin(), fruits2.end(),
std::inserter(result, result.begin()));
std::cout << "Elements in fruits1 but not in fruits2: ";
for (const auto& fruit : result) {
std::cout << fruit << " ";
}
return 0;
}
Output:
Elements in fruits1 but not in fruits2: apple cherry
🔑 Key Point: The set_difference() algorithm is order-sensitive. Swapping the order of the sets will give you a different result.
4. Symmetric Difference
The symmetric difference finds elements that are in either set, but not in both. We can implement this using set_symmetric_difference():
#include <iostream>
#include <set>
#include <algorithm>
#include <iterator>
int main() {
std::set<int> set1 {1, 2, 3, 4, 5};
std::set<int> set2 {3, 4, 5, 6, 7};
std::set<int> result;
std::set_symmetric_difference(set1.begin(), set1.end(),
set2.begin(), set2.end(),
std::inserter(result, result.begin()));
std::cout << "Symmetric difference of set1 and set2: ";
for (int num : result) {
std::cout << num << " ";
}
return 0;
}
Output:
Symmetric difference of set1 and set2: 1 2 6 7
💡 Tip: The symmetric difference is useful when you want to find elements that are unique to each set.
Performance Considerations
When working with set operations, it's important to consider performance:
| Operation | Time Complexity |
|---|---|
| Insert | O(log n) |
| Erase | O(log n) |
| Search | O(log n) |
| Union | O(n + m) |
| Intersection | O(n + m) |
| Difference | O(n + m) |
🔑 Key Point: Set operations are generally efficient, especially for large datasets, due to the sorted nature of sets.
Custom Comparators
C++ sets allow you to define custom comparators to change the ordering of elements. This is particularly useful when working with complex objects:
#include <iostream>
#include <set>
#include <string>
struct Person {
std::string name;
int age;
bool operator<(const Person& other) const {
return age < other.age;
}
};
int main() {
std::set<Person> people;
people.insert({"Alice", 30});
people.insert({"Bob", 25});
people.insert({"Charlie", 35});
for (const auto& person : people) {
std::cout << person.name << ": " << person.age << std::endl;
}
return 0;
}
Output:
Bob: 25
Alice: 30
Charlie: 35
💡 Tip: By defining the operator<, we've made the set order people by age.
Practical Example: Word Frequency Counter
Let's put our knowledge of sets to practical use by creating a word frequency counter:
#include <iostream>
#include <set>
#include <map>
#include <string>
#include <sstream>
#include <algorithm>
int main() {
std::string text = "the quick brown fox jumps over the lazy dog";
std::istringstream iss(text);
std::set<std::string> unique_words;
std::map<std::string, int> word_count;
std::string word;
while (iss >> word) {
unique_words.insert(word);
word_count[word]++;
}
std::cout << "Unique words:" << std::endl;
for (const auto& w : unique_words) {
std::cout << w << " ";
}
std::cout << std::endl << std::endl;
std::cout << "Word frequencies:" << std::endl;
for (const auto& pair : word_count) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
Output:
Unique words:
brown dog fox jumps lazy over quick the
Word frequencies:
brown: 1
dog: 1
fox: 1
jumps: 1
lazy: 1
over: 1
quick: 1
the: 2
🔍 Note: This example demonstrates how sets can be used to efficiently track unique elements, while a map is used to count occurrences.
Conclusion
C++ set methods and operations provide powerful tools for managing collections of unique elements. From basic operations like insertion and deletion to more advanced set operations like union and intersection, sets offer efficient and flexible ways to manipulate data.
By mastering these set operations, you'll be well-equipped to tackle a wide range of programming challenges that involve unique collections of elements. Remember to consider the performance implications of your operations, especially when working with large datasets.
🚀 Challenge: Try implementing a program that finds the common words between two texts using set operations. This will help reinforce your understanding of set intersections and differences.
Happy coding, and may your sets always be perfectly balanced! 🎭
Related Posts

C++ Set: Unique Unordered Elements
In the world of C++ programming, efficient data management is crucial. Enter the C++ Set - a powerful container that...
C++ Multiset: Non-Unique Ordered Elements
In the vast landscape of C++ containers, the multiset stands out as a unique and powerful tool for managing collections...

C++ Map: Key-Value Pairs
In the world of C++ programming, efficient data management is crucial. Enter the C++ map container – a powerful tool...
C++ Arrays: Creating and Using Arrays
Arrays are fundamental data structures in C++ that allow you to store multiple elements of the same data type in...

C++ Map Methods: Key-Value Pair Operations
In the world of C++, the std::map container is a powerful tool for managing key-value pairs. It's an associative container...

C++ Unordered Containers: Hash-Based Data Structures
In the world of C++ programming, efficiency and performance are paramount. When it comes to storing and retrieving data quickly,...

C++ Multimap: Multiple Values for Keys
In the world of C++ containers, the multimap stands out as a versatile and powerful tool for managing collections of...

C++ How To: Implement Binary Search
Binary search is a fundamental algorithm in computer science that efficiently locates a target value within a sorted array. This...

C++ Ranges: Composable Algorithms (C++20)
C++20 introduced a powerful new feature to the language: Ranges. This addition revolutionizes the way we work with collections and...
Python set() Function: Creating Sets
The set() function in Python is a powerful tool for working with unordered collections of unique elements. Sets are mutable,...

C++ Algorithm Functions: Standard Library Algorithm Operations
C++ provides a powerful set of algorithm functions in its Standard Template Library (STL) that can significantly simplify and optimize...
C++ Data Types: Primitives and User-Defined Types
C++ is a powerful, versatile programming language that offers a rich set of data types to handle various kinds of...