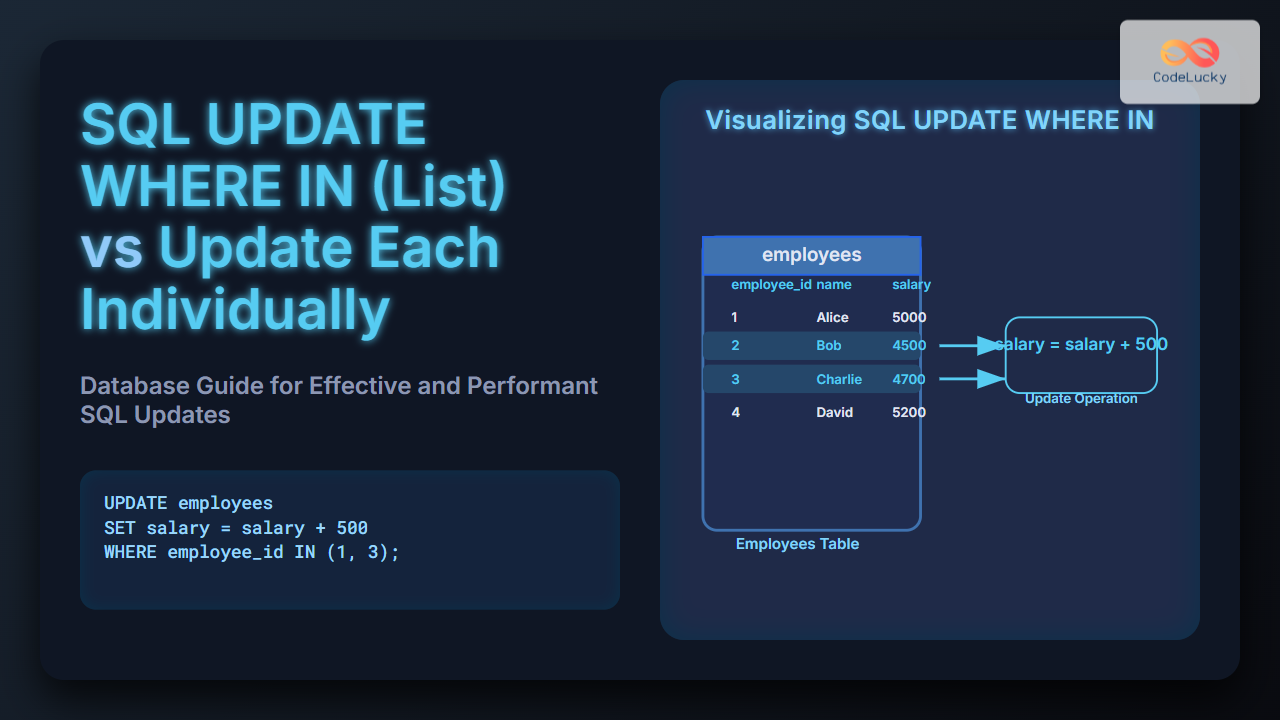
SQL window functions are powerful tools that allow you to perform complex calculations across a set of rows that are somehow related to the current row. These functions operate on a window of data, which is a set of rows defined by a partition and an ordering within that partition. Window functions open up a world of possibilities for data analysis, enabling you to solve problems that would be difficult or impossible with standard SQL aggregations.
In this comprehensive guide, we'll dive deep into SQL window functions, exploring their syntax, use cases, and advanced applications. We'll cover a range of functions, from ranking and running totals to moving averages and lag/lead comparisons. By the end of this article, you'll have a solid understanding of how to leverage these powerful functions in your SQL queries.
Understanding Window Functions
Before we delve into specific functions, let's understand the basic syntax and concept of window functions.
function_name() OVER (
[PARTITION BY column1, column2, ...]
[ORDER BY column3, column4, ...]
[ROWS or RANGE frame_clause]
)
function_name(): This is the window function you want to apply (e.g., ROW_NUMBER(), RANK(), SUM(), etc.).OVER: This keyword indicates that we're using a window function.PARTITION BY: This optional clause divides the result set into partitions to which the function is applied separately.ORDER BY: This optional clause defines the logical order of rows within each partition.ROWS or RANGE: This optional clause further refines the set of rows within the partition.
Now, let's explore some powerful window functions with practical examples.
🏆 Ranking Functions
Ranking functions are among the most commonly used window functions. They assign a rank to each row within a partition based on the values in one or more columns.
ROW_NUMBER()
The ROW_NUMBER() function assigns a unique integer to each row within a partition.
Let's consider a table of employees:
CREATE TABLE employees (
emp_id INT,
emp_name VARCHAR(50),
department VARCHAR(50),
salary DECIMAL(10, 2)
);
INSERT INTO employees VALUES
(1, 'John Doe', 'Sales', 50000),
(2, 'Jane Smith', 'Marketing', 60000),
(3, 'Bob Johnson', 'Sales', 55000),
(4, 'Alice Brown', 'HR', 52000),
(5, 'Charlie Davis', 'Marketing', 58000);
Now, let's assign a unique number to each employee within their department:
SELECT
emp_id,
emp_name,
department,
salary,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM
employees;
Result:
| emp_id | emp_name | department | salary | dept_rank |
|---|---|---|---|---|
| 2 | Jane Smith | Marketing | 60000.00 | 1 |
| 5 | Charlie Davis | Marketing | 58000.00 | 2 |
| 3 | Bob Johnson | Sales | 55000.00 | 1 |
| 1 | John Doe | Sales | 50000.00 | 2 |
| 4 | Alice Brown | HR | 52000.00 | 1 |
In this example, ROW_NUMBER() assigns a unique rank to each employee within their department, ordered by salary in descending order.
RANK() and DENSE_RANK()
RANK() and DENSE_RANK() are similar to ROW_NUMBER(), but they handle ties differently.
SELECT
emp_id,
emp_name,
department,
salary,
RANK() OVER (ORDER BY salary DESC) AS overall_rank,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank
FROM
employees;
Result:
| emp_id | emp_name | department | salary | overall_rank | dense_rank |
|---|---|---|---|---|---|
| 2 | Jane Smith | Marketing | 60000.00 | 1 | 1 |
| 5 | Charlie Davis | Marketing | 58000.00 | 2 | 2 |
| 3 | Bob Johnson | Sales | 55000.00 | 3 | 3 |
| 4 | Alice Brown | HR | 52000.00 | 4 | 4 |
| 1 | John Doe | Sales | 50000.00 | 5 | 5 |
RANK() leaves gaps in the ranking when there are ties, while DENSE_RANK() does not. If we had two employees with the same salary, RANK() might give ranks like 1, 2, 2, 4, while DENSE_RANK() would give 1, 2, 2, 3.
📊 Aggregate Window Functions
Aggregate window functions allow you to perform calculations across a set of rows that are related to the current row.
Running Total
Let's calculate a running total of salaries within each department:
SELECT
emp_id,
emp_name,
department,
salary,
SUM(salary) OVER (
PARTITION BY department
ORDER BY emp_id
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS running_total
FROM
employees;
Result:
| emp_id | emp_name | department | salary | running_total |
|---|---|---|---|---|
| 1 | John Doe | Sales | 50000.00 | 50000.00 |
| 3 | Bob Johnson | Sales | 55000.00 | 105000.00 |
| 2 | Jane Smith | Marketing | 60000.00 | 60000.00 |
| 5 | Charlie Davis | Marketing | 58000.00 | 118000.00 |
| 4 | Alice Brown | HR | 52000.00 | 52000.00 |
This query calculates the running total of salaries within each department, ordered by employee ID.
Moving Average
Moving averages are useful for smoothing out short-term fluctuations and highlighting longer-term trends or cycles. Let's calculate a 3-day moving average of sales:
CREATE TABLE daily_sales (
sale_date DATE,
total_sales DECIMAL(10, 2)
);
INSERT INTO daily_sales VALUES
('2023-06-01', 1000),
('2023-06-02', 1200),
('2023-06-03', 800),
('2023-06-04', 1500),
('2023-06-05', 1100),
('2023-06-06', 1300),
('2023-06-07', 900);
SELECT
sale_date,
total_sales,
AVG(total_sales) OVER (
ORDER BY sale_date
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS moving_avg
FROM
daily_sales;
Result:
| sale_date | total_sales | moving_avg |
|---|---|---|
| 2023-06-01 | 1000.00 | 1000.000000 |
| 2023-06-02 | 1200.00 | 1100.000000 |
| 2023-06-03 | 800.00 | 1000.000000 |
| 2023-06-04 | 1500.00 | 1166.666667 |
| 2023-06-05 | 1100.00 | 1133.333333 |
| 2023-06-06 | 1300.00 | 1300.000000 |
| 2023-06-07 | 900.00 | 1100.000000 |
This query calculates a 3-day moving average of sales. For each day, it averages the sales for that day and the two preceding days.
🔄 Offset Window Functions
Offset functions allow you to access data from other rows in relation to the current row.
LAG() and LEAD()
LAG() accesses data from a previous row, while LEAD() accesses data from a subsequent row.
SELECT
sale_date,
total_sales,
LAG(total_sales) OVER (ORDER BY sale_date) AS prev_day_sales,
LEAD(total_sales) OVER (ORDER BY sale_date) AS next_day_sales
FROM
daily_sales;
Result:
| sale_date | total_sales | prev_day_sales | next_day_sales |
|---|---|---|---|
| 2023-06-01 | 1000.00 | NULL | 1200.00 |
| 2023-06-02 | 1200.00 | 1000.00 | 800.00 |
| 2023-06-03 | 800.00 | 1200.00 | 1500.00 |
| 2023-06-04 | 1500.00 | 800.00 | 1100.00 |
| 2023-06-05 | 1100.00 | 1500.00 | 1300.00 |
| 2023-06-06 | 1300.00 | 1100.00 | 900.00 |
| 2023-06-07 | 900.00 | 1300.00 | NULL |
This query shows the sales for each day, along with the sales from the previous day and the next day.
🔢 Ntile Function
The NTILE function divides the rows into a specified number of ranked groups.
SELECT
emp_id,
emp_name,
salary,
NTILE(4) OVER (ORDER BY salary DESC) AS salary_quartile
FROM
employees;
Result:
| emp_id | emp_name | salary | salary_quartile |
|---|---|---|---|
| 2 | Jane Smith | 60000.00 | 1 |
| 5 | Charlie Davis | 58000.00 | 1 |
| 3 | Bob Johnson | 55000.00 | 2 |
| 4 | Alice Brown | 52000.00 | 3 |
| 1 | John Doe | 50000.00 | 4 |
This query divides the employees into four groups based on their salary, with group 1 being the highest paid and group 4 being the lowest paid.
🧮 Advanced Calculations
Now that we've covered the basics, let's look at some more advanced calculations using window functions.
Percentage of Total
Let's calculate each employee's salary as a percentage of their department's total salary:
SELECT
emp_id,
emp_name,
department,
salary,
ROUND(
salary / SUM(salary) OVER (PARTITION BY department) * 100,
2
) AS pct_of_dept_total
FROM
employees;
Result:
| emp_id | emp_name | department | salary | pct_of_dept_total |
|---|---|---|---|---|
| 2 | Jane Smith | Marketing | 60000.00 | 50.85 |
| 5 | Charlie Davis | Marketing | 58000.00 | 49.15 |
| 1 | John Doe | Sales | 50000.00 | 47.62 |
| 3 | Bob Johnson | Sales | 55000.00 | 52.38 |
| 4 | Alice Brown | HR | 52000.00 | 100.00 |
This query calculates each employee's salary as a percentage of their department's total salary.
Cumulative Distribution
The CUME_DIST() function calculates the cumulative distribution of a value within a set of values.
SELECT
emp_id,
emp_name,
salary,
ROUND(
CUME_DIST() OVER (ORDER BY salary),
2
) AS salary_percentile
FROM
employees;
Result:
| emp_id | emp_name | salary | salary_percentile |
|---|---|---|---|
| 1 | John Doe | 50000.00 | 0.20 |
| 4 | Alice Brown | 52000.00 | 0.40 |
| 3 | Bob Johnson | 55000.00 | 0.60 |
| 5 | Charlie Davis | 58000.00 | 0.80 |
| 2 | Jane Smith | 60000.00 | 1.00 |
This query calculates the salary percentile for each employee. For example, 20% of employees earn less than or equal to John Doe's salary.
First Value and Last Value
The FIRST_VALUE and LAST_VALUE functions allow you to get the first and last values in an ordered set of values.
SELECT
emp_id,
emp_name,
department,
salary,
FIRST_VALUE(emp_name) OVER (
PARTITION BY department
ORDER BY salary DESC
) AS highest_paid_in_dept,
LAST_VALUE(emp_name) OVER (
PARTITION BY department
ORDER BY salary DESC
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS lowest_paid_in_dept
FROM
employees;
Result:
| emp_id | emp_name | department | salary | highest_paid_in_dept | lowest_paid_in_dept |
|---|---|---|---|---|---|
| 2 | Jane Smith | Marketing | 60000.00 | Jane Smith | Charlie Davis |
| 5 | Charlie Davis | Marketing | 58000.00 | Jane Smith | Charlie Davis |
| 3 | Bob Johnson | Sales | 55000.00 | Bob Johnson | John Doe |
| 1 | John Doe | Sales | 50000.00 | Bob Johnson | John Doe |
| 4 | Alice Brown | HR | 52000.00 | Alice Brown | Alice Brown |
This query shows the highest and lowest paid employees in each department.
🚀 Performance Considerations
While window functions are powerful, they can be computationally expensive, especially on large datasets. Here are some tips to optimize performance:
-
Use appropriate indexes: Ensure that columns used in PARTITION BY and ORDER BY clauses are properly indexed.
-
Limit the window size: When possible, use ROWS or RANGE to limit the window size instead of using the entire partition.
-
Avoid unnecessary partitioning: If you don't need to partition the data, don't use PARTITION BY.
-
Combine window functions: Instead of using multiple queries with different window functions, try to combine them into a single query.
-
Use CTEs or subqueries: Sometimes, it's more efficient to calculate window functions in a CTE or subquery and then join or reference the results.
🎓 Conclusion
SQL window functions are a powerful feature that can greatly enhance your data analysis capabilities. They allow you to perform complex calculations and comparisons across related rows of data, opening up new possibilities for insight generation.
In this article, we've covered a wide range of window functions, from basic ranking and aggregation to more advanced calculations like cumulative distribution and moving averages. We've seen how these functions can be used to solve real-world problems, such as calculating running totals, identifying top performers, and analyzing trends over time.
Remember, the key to mastering window functions is practice. Try incorporating these functions into your own queries, experiment with different scenarios, and you'll soon find yourself reaching for window functions to solve complex analytical problems with ease.
As you continue to work with window functions, you'll discover even more applications and nuances. They're a valuable tool in any SQL developer's toolkit, enabling you to write more efficient and expressive queries and unlock deeper insights from your data.
Happy querying! 🎉
Related Posts

SQL SUM() Function: Totaling Values
SQL's SUM() function is a powerful tool in a data analyst's arsenal, allowing for quick and efficient calculation of numerical...

Excel AGGREGATE Function: Complete Guide to Advanced Statistical Calculations
Excel's AGGREGATE function is one of the most powerful and versatile statistical functions available in Microsoft Excel. Unlike traditional statistical...

MySQL SUM Function: Mastering Numeric Aggregation
The SUM() function in MySQL is a powerful tool for aggregating numeric data. It allows you to calculate the total...

SQL COUNT() Function: Counting Records
In the world of databases, counting records is a fundamental operation that provides valuable insights into your data. The SQL...

SQL AVG() Function: Calculating the Average
In the world of data analysis and database management, the ability to calculate averages is a fundamental skill. The SQL...

SQL Operators: Beyond Basic Arithmetic
SQL, the lingua franca of data manipulation, is more than just a tool for retrieving information from databases. It's a...

SQL Numeric Functions: Mathematical Operations
SQL isn't just about retrieving and manipulating data; it's also a powerful tool for performing mathematical operations. Whether you're calculating...

MySQL Numeric Functions: Mastering Mathematical Operations
MySQL numeric functions are essential for performing calculations and manipulating numerical data within your database. Whether you're calculating totals, averages,...

SQL Server Functions: Built-in Tools for Data Manipulation
SQL Server functions are powerful built-in tools that allow you to manipulate and transform data efficiently. These functions can significantly...

SQL MAX() Function: Retrieving the Largest Value
SQL's MAX() function is a powerful tool in a database developer's arsenal, allowing you to quickly find the highest value...

MySQL Mathematical Operators: Arithmetic in SQL
Mathematical operators are essential tools in MySQL, allowing you to perform calculations directly within your SQL queries. Whether you're computing...
MySQL Functions: Mastering Data Manipulation and Transformation
MySQL functions are the workhorses of data manipulation and transformation. They enable you to perform calculations, modify strings, manipulate dates,...