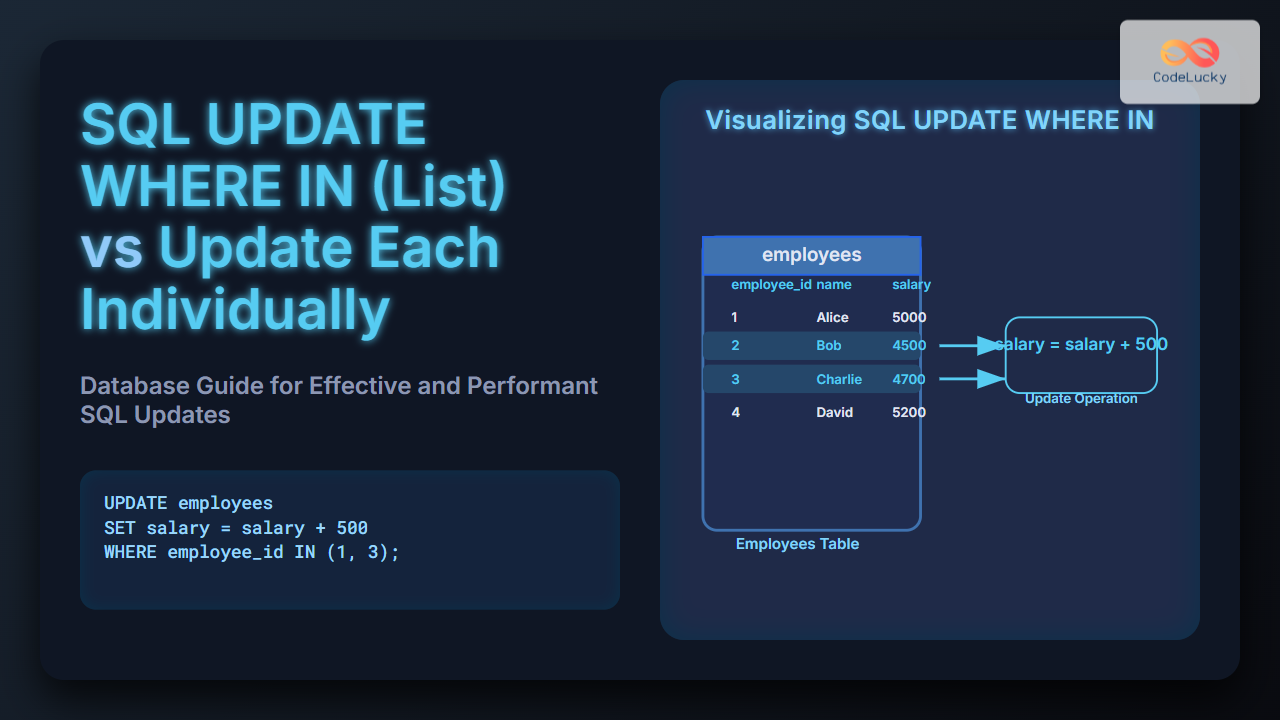
In the world of database management, ensuring data integrity while allowing multiple users to access and modify data simultaneously is a critical challenge. SQL table locking is a powerful mechanism that helps database administrators and developers manage concurrent access to tables, preventing data conflicts and maintaining consistency. In this comprehensive guide, we'll dive deep into the intricacies of SQL table locking, exploring various locking techniques, their implications, and best practices for implementation.
Understanding SQL Table Locking
SQL table locking is a method used by database management systems (DBMS) to control access to tables during concurrent operations. When a lock is placed on a table, it restricts other transactions from accessing or modifying the data until the lock is released. This ensures data integrity and prevents issues such as lost updates, dirty reads, and inconsistent analysis.
🔒 Key Concept: Table locking is essential for maintaining ACID (Atomicity, Consistency, Isolation, Durability) properties in database transactions.
Types of Locks
There are several types of locks that can be applied to tables in SQL:
- Shared (S) Lock: Allows multiple transactions to read data simultaneously but prevents any writes.
- Exclusive (X) Lock: Prevents other transactions from reading or writing to the locked resource.
- Update (U) Lock: Used when a transaction intends to update data but hasn't yet modified it.
- Intent Locks: Indicate the intention to acquire shared or exclusive locks on lower-level resources.
Let's explore each of these lock types with practical examples.
Shared (S) Lock
A shared lock allows multiple transactions to read data concurrently but prevents any writes. This is useful for maintaining data consistency during read operations.
-- Transaction 1
BEGIN TRANSACTION;
SELECT * FROM Employees WITH (HOLDLOCK, ROWLOCK)
WHERE Department = 'IT';
-- Other operations...
COMMIT;
-- Transaction 2 (can run concurrently)
BEGIN TRANSACTION;
SELECT * FROM Employees WITH (HOLDLOCK, ROWLOCK)
WHERE Department = 'HR';
-- Other operations...
COMMIT;
In this example, both transactions can read from the Employees table simultaneously, but neither can modify the data until their respective transactions are committed.
Exclusive (X) Lock
An exclusive lock prevents other transactions from reading or writing to the locked resource. This is crucial for maintaining data integrity during write operations.
-- Transaction 1
BEGIN TRANSACTION;
UPDATE Employees
SET Salary = Salary * 1.1
WHERE Department = 'Sales';
-- Other operations...
COMMIT;
-- Transaction 2 (will be blocked until Transaction 1 commits)
BEGIN TRANSACTION;
SELECT * FROM Employees
WHERE Department = 'Sales';
-- Other operations...
COMMIT;
In this scenario, Transaction 1 acquires an exclusive lock on the Employees table for the Sales department. Transaction 2 will be blocked from reading or writing to the same rows until Transaction 1 commits.
Update (U) Lock
An update lock is used when a transaction intends to update data but hasn't yet modified it. This prevents other transactions from acquiring an exclusive lock on the same resource.
-- Transaction 1
BEGIN TRANSACTION;
SELECT * FROM Inventory WITH (UPDLOCK)
WHERE ProductID = 101;
-- Check inventory and decide whether to update
IF (SELECT Quantity FROM Inventory WHERE ProductID = 101) > 10
BEGIN
UPDATE Inventory
SET Quantity = Quantity - 10
WHERE ProductID = 101;
END
COMMIT;
In this example, the update lock is acquired when selecting the inventory data. This allows the transaction to check the quantity and decide whether to update it without the risk of another transaction modifying the data in between.
Intent Locks
Intent locks indicate the intention to acquire shared or exclusive locks on lower-level resources. They are used in hierarchical locking schemes.
-- Transaction 1
BEGIN TRANSACTION;
SELECT * FROM Orders WITH (TABLOCK, HOLDLOCK)
WHERE OrderDate = CAST(GETDATE() AS DATE);
-- Other operations...
COMMIT;
-- Transaction 2 (will be blocked for the entire Orders table)
BEGIN TRANSACTION;
INSERT INTO Orders (CustomerID, OrderDate, TotalAmount)
VALUES (1001, GETDATE(), 500.00);
COMMIT;
In this case, Transaction 1 acquires a table-level shared lock (TABLOCK) on the Orders table. Transaction 2 will be blocked from inserting new orders until Transaction 1 commits, even if it's inserting data for a different date.
Lock Granularity
Lock granularity refers to the level at which locks are applied. Common levels include:
- Table-level locks: Applied to entire tables
- Page-level locks: Applied to database pages (typically 8KB)
- Row-level locks: Applied to individual rows
🔍 Fact: Finer granularity (e.g., row-level locks) allows for better concurrency but increases overhead, while coarser granularity (e.g., table-level locks) reduces overhead but may limit concurrency.
Let's examine how different lock granularities affect concurrent access:
-- Table-level lock
BEGIN TRANSACTION;
SELECT * FROM Customers WITH (TABLOCK);
-- Other operations...
COMMIT;
-- Page-level lock
BEGIN TRANSACTION;
SELECT * FROM Customers WITH (PAGLOCK);
-- Other operations...
COMMIT;
-- Row-level lock
BEGIN TRANSACTION;
SELECT * FROM Customers WITH (ROWLOCK)
WHERE CustomerID = 1001;
-- Other operations...
COMMIT;
In the table-level lock example, the entire Customers table is locked, preventing any other transactions from accessing it. With page-level locking, only the affected pages are locked, allowing more concurrent access. Row-level locking provides the highest level of concurrency by locking only the specific rows being accessed.
Deadlocks and Their Resolution
A deadlock occurs when two or more transactions are waiting for each other to release locks, resulting in a circular dependency. DBMSs typically have built-in deadlock detection and resolution mechanisms.
Consider this deadlock scenario:
-- Transaction 1
BEGIN TRANSACTION;
UPDATE Accounts SET Balance = Balance - 100 WHERE AccountID = 1001;
-- Wait for 5 seconds to simulate processing time
WAITFOR DELAY '00:00:05';
UPDATE Accounts SET Balance = Balance + 100 WHERE AccountID = 1002;
COMMIT;
-- Transaction 2 (running concurrently)
BEGIN TRANSACTION;
UPDATE Accounts SET Balance = Balance - 200 WHERE AccountID = 1002;
-- Wait for 5 seconds to simulate processing time
WAITFOR DELAY '00:00:05';
UPDATE Accounts SET Balance = Balance + 200 WHERE AccountID = 1001;
COMMIT;
In this example, Transaction 1 locks AccountID 1001 and waits to lock 1002, while Transaction 2 locks AccountID 1002 and waits to lock 1001. This results in a deadlock.
To resolve deadlocks, DBMSs typically choose one transaction as the "victim" and roll it back. The choice is often based on factors such as:
- Transaction with the least amount of work done
- Transaction holding the fewest locks
- First transaction to reach a timeout
💡 Best Practice: To minimize deadlocks, always access resources in the same order across transactions and keep transactions as short as possible.
Optimistic vs. Pessimistic Locking
SQL table locking strategies can be broadly categorized into two approaches:
Pessimistic Locking
Pessimistic locking assumes that conflicts are likely to occur and locks resources preemptively. This approach is suitable for high-contention scenarios but may reduce concurrency.
BEGIN TRANSACTION;
-- Acquire an exclusive lock on the product
SELECT * FROM Products WITH (XLOCK, ROWLOCK)
WHERE ProductID = 101;
-- Check if there's enough inventory
IF (SELECT Quantity FROM Products WHERE ProductID = 101) >= 10
BEGIN
-- Update the inventory
UPDATE Products
SET Quantity = Quantity - 10
WHERE ProductID = 101;
-- Insert the order details
INSERT INTO OrderDetails (OrderID, ProductID, Quantity)
VALUES (1001, 101, 10);
COMMIT;
END
ELSE
BEGIN
-- Not enough inventory
ROLLBACK;
END
In this example, an exclusive lock is acquired on the product before checking and updating the inventory. This prevents any other transactions from modifying the product's quantity until the current transaction completes.
Optimistic Locking
Optimistic locking assumes that conflicts are rare and checks for conflicts only at the time of update. This approach allows for higher concurrency but may require additional application logic to handle conflicts.
BEGIN TRANSACTION;
-- Read the current product data
DECLARE @OriginalQuantity INT;
SELECT @OriginalQuantity = Quantity
FROM Products
WHERE ProductID = 101;
-- Simulate some processing time
WAITFOR DELAY '00:00:02';
-- Attempt to update the inventory
UPDATE Products
SET Quantity = Quantity - 10
WHERE ProductID = 101
AND Quantity = @OriginalQuantity;
IF @@ROWCOUNT = 0
BEGIN
-- Conflict detected, handle accordingly (e.g., retry or notify user)
PRINT 'Update conflict detected. Please try again.';
ROLLBACK;
END
ELSE
BEGIN
-- Update successful, proceed with order insertion
INSERT INTO OrderDetails (OrderID, ProductID, Quantity)
VALUES (1001, 101, 10);
COMMIT;
END
In this optimistic locking approach, we first read the current quantity, perform some processing, and then attempt to update the inventory only if the quantity hasn't changed. If a conflict is detected (i.e., the quantity has changed), we handle it appropriately.
Performance Considerations
While table locking is crucial for maintaining data integrity, it can impact database performance if not implemented carefully. Here are some performance considerations:
- Lock Duration: Minimize the time locks are held by keeping transactions as short as possible.
- Lock Granularity: Use the appropriate lock granularity based on your specific use case and concurrency requirements.
- Index Usage: Properly indexed tables can reduce the number of locks required and improve overall performance.
- Lock Escalation: Be aware of lock escalation, where multiple fine-grained locks are converted to a single coarse-grained lock, which can impact concurrency.
Let's examine a scenario where proper indexing can significantly improve locking performance:
-- Create a non-clustered index on the OrderDate column
CREATE NONCLUSTERED INDEX IX_Orders_OrderDate
ON Orders (OrderDate);
-- Query using the index
BEGIN TRANSACTION;
SELECT * FROM Orders WITH (ROWLOCK)
WHERE OrderDate = '2023-05-01';
-- Other operations...
COMMIT;
By creating an index on the OrderDate column, we allow the query to use row-level locking efficiently, locking only the relevant rows instead of scanning and locking the entire table.
Monitoring and Troubleshooting Locks
To effectively manage table locking in your SQL database, it's essential to monitor and troubleshoot locking issues. SQL Server provides several tools and dynamic management views (DMVs) for this purpose:
- sys.dm_tran_locks: This DMV provides information about currently active lock objects.
SELECT
resource_type,
resource_description,
request_mode,
request_status
FROM sys.dm_tran_locks
WHERE resource_database_id = DB_ID();
- sp_who2: This system stored procedure shows information about current users, sessions, and processes.
EXEC sp_who2;
- Extended Events: You can use Extended Events to capture detailed information about locking and blocking events.
-- Create an Extended Events session to capture lock timeouts
CREATE EVENT SESSION [LockTimeouts] ON SERVER
ADD EVENT sqlserver.lock_timeout
ADD TARGET package0.event_file(SET filename=N'C:\Temp\LockTimeouts.xel')
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,
TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
GO
-- Start the Extended Events session
ALTER EVENT SESSION [LockTimeouts] ON SERVER STATE = START;
By regularly monitoring these resources, you can identify and address locking issues before they become critical problems.
Best Practices for SQL Table Locking
To effectively manage concurrent access using SQL table locking, consider the following best practices:
-
Use appropriate isolation levels: Choose the right isolation level for your transactions based on your consistency and concurrency requirements.
-
Keep transactions short: Minimize the duration of locks by keeping transactions as short as possible.
-
Access resources in a consistent order: To prevent deadlocks, ensure that all transactions access resources in the same order.
-
Use row-level locking when possible: Row-level locking provides better concurrency for most scenarios.
-
Implement retry logic: For optimistic locking scenarios, implement retry logic in your application to handle conflicts.
-
Regularly monitor locking activity: Use the monitoring tools discussed earlier to identify and address locking issues proactively.
-
Optimize queries and indexes: Well-optimized queries and appropriate indexes can significantly reduce locking contention.
-
Consider using snapshot isolation: For read-heavy workloads, snapshot isolation can provide better concurrency without sacrificing consistency.
-
Test thoroughly: Always test your locking strategies under realistic concurrent load to ensure they perform as expected.
Conclusion
SQL table locking is a powerful mechanism for managing concurrent access to database resources. By understanding the various types of locks, their granularity, and the strategies for implementing them, you can design robust and efficient database systems that maintain data integrity while maximizing concurrency.
Remember that effective table locking is a balancing act between ensuring data consistency and allowing for high levels of concurrent access. By following the best practices outlined in this guide and continuously monitoring and optimizing your locking strategies, you can create database applications that are both reliable and performant.
As you continue to work with SQL databases, keep exploring advanced locking techniques and stay updated with the latest features offered by your specific DBMS. With practice and experience, you'll develop the skills to implement sophisticated locking strategies that meet the unique needs of your applications and users.
Related Posts
SQL Transactions: Ensuring Data Integrity
In the world of database management, maintaining data integrity is paramount. SQL transactions play a crucial role in this process,...

SQL Constraints: Enforcing Rules on Your Data
In the world of database management, maintaining data integrity is paramount. SQL constraints are the guardians of this integrity, ensuring...
MySQL Transactions: Ensuring Data Integrity and Consistency
Transactions are the backbone of reliable database management. They allow you to group a sequence of database operations into a...

Readers Writers Problem: Complete Guide to Database Synchronization
The Readers Writers Problem is one of the most fundamental synchronization challenges in operating systems and database management. This classic...
SQL COMMIT Statement: Saving Transaction Changes Permanently
In the world of database management, ensuring data integrity and consistency is paramount. One of the key tools in achieving...

SQL CHECK Constraint: Validating Data in Tables
In the world of database management, ensuring data integrity is paramount. One powerful tool in the SQL arsenal for maintaining...

SQL FOREIGN KEY: Linking Tables in Databases
In the world of relational databases, data is often spread across multiple tables. While this approach helps maintain data integrity...

File Locking Mechanisms: Complete Guide to Advisory and Mandatory Locking in Operating Systems
File locking mechanisms are essential components of modern operating systems that prevent data corruption and ensure data integrity when multiple...

C++ Atomic Operations: Lock-Free Programming
In the world of modern C++ programming, concurrency and parallelism have become increasingly important. As developers, we often need to...
SQL ROLLBACK Statement: Undoing Changes in Transactions
In the world of database management, ensuring data integrity and consistency is paramount. One of the most powerful tools in...

SQL UNIQUE Constraint: Preventing Duplicate Values
In the world of database management, ensuring data integrity is paramount. One of the key aspects of maintaining data integrity...

SQL PRIMARY KEY: Defining Unique Identifiers in Tables
In the world of relational databases, the concept of a PRIMARY KEY is fundamental to maintaining data integrity and establishing...