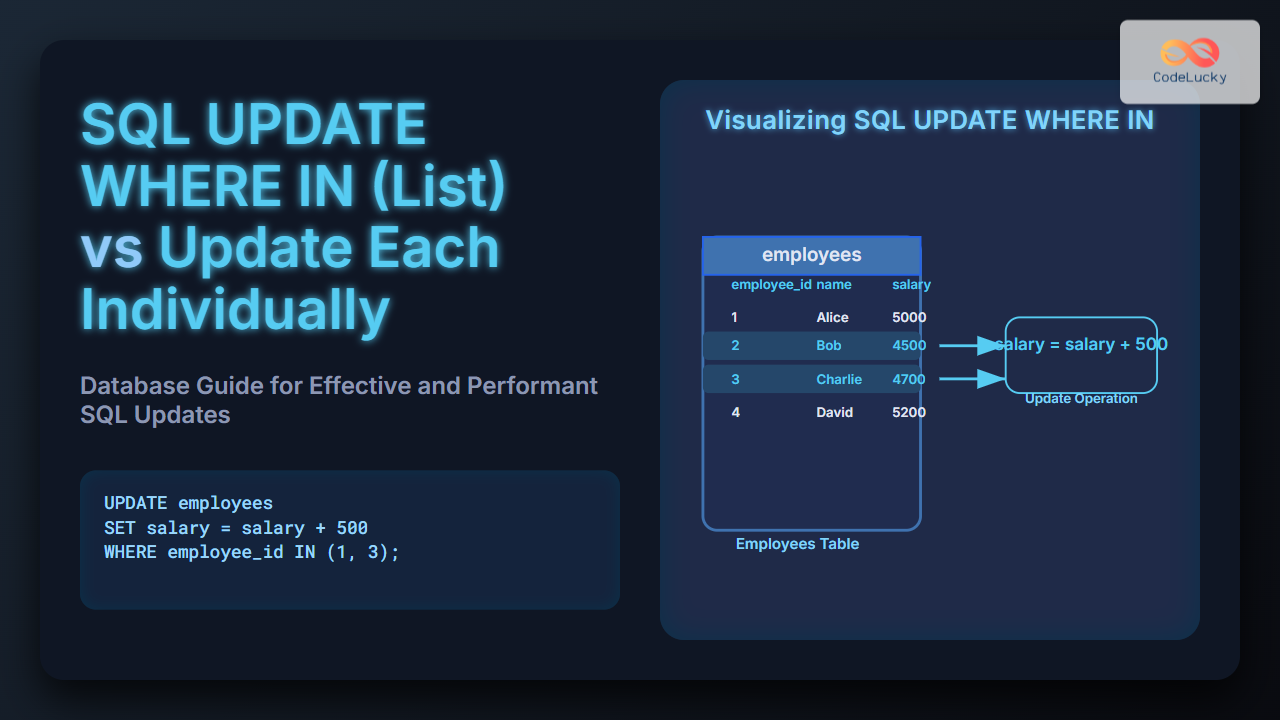
In the world of relational databases, the concept of a PRIMARY KEY is fundamental to maintaining data integrity and establishing relationships between tables. This article will dive deep into the intricacies of PRIMARY KEYs in SQL, exploring their importance, implementation, and best practices.
What is a PRIMARY KEY?
A PRIMARY KEY is a column or a set of columns in a table that uniquely identifies each row. It serves as a unique identifier for records within the table, ensuring that no two rows can have the same value(s) in the PRIMARY KEY column(s).
🔑 Key Facts:
- A PRIMARY KEY must contain UNIQUE values
- A PRIMARY KEY cannot contain NULL values
- A table can have only ONE PRIMARY KEY
Why Use a PRIMARY KEY?
- Uniqueness: Ensures each record in the table is uniquely identifiable.
- Data Integrity: Prevents duplicate or inconsistent data.
- Relationships: Allows other tables to reference specific rows, enabling table relationships.
- Indexing: Improves query performance as databases automatically create an index on PRIMARY KEY columns.
Creating Tables with PRIMARY KEYs
Let's explore different ways to create tables with PRIMARY KEYs using SQL.
Single Column PRIMARY KEY
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100)
);
In this example, employee_id is set as the PRIMARY KEY. Each employee will have a unique employee_id.
Composite PRIMARY KEY
A composite PRIMARY KEY consists of two or more columns.
CREATE TABLE order_items (
order_id INT,
product_id INT,
quantity INT,
price DECIMAL(10, 2),
PRIMARY KEY (order_id, product_id)
);
Here, the combination of order_id and product_id forms the PRIMARY KEY. This allows multiple products per order while ensuring no duplicate entries for the same product in a single order.
PRIMARY KEY with CONSTRAINT Keyword
You can also define a PRIMARY KEY using the CONSTRAINT keyword:
CREATE TABLE customers (
customer_id INT,
company_name VARCHAR(100),
contact_name VARCHAR(100),
CONSTRAINT pk_customer PRIMARY KEY (customer_id)
);
This method allows you to name the constraint, which can be useful for future alterations or when troubleshooting.
Adding a PRIMARY KEY to an Existing Table
If you need to add a PRIMARY KEY to a table that already exists, you can use the ALTER TABLE statement:
ALTER TABLE products
ADD PRIMARY KEY (product_id);
This assumes that product_id already exists in the table and contains unique, non-null values.
AUTO INCREMENT with PRIMARY KEY
Many database systems allow you to automatically generate unique values for PRIMARY KEYs using an AUTO INCREMENT feature. The syntax varies slightly between different database management systems:
MySQL
CREATE TABLE books (
book_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(100),
author VARCHAR(100),
publication_year INT
);
SQL Server
CREATE TABLE books (
book_id INT IDENTITY(1,1) PRIMARY KEY,
title VARCHAR(100),
author VARCHAR(100),
publication_year INT
);
PostgreSQL
CREATE TABLE books (
book_id SERIAL PRIMARY KEY,
title VARCHAR(100),
author VARCHAR(100),
publication_year INT
);
In each of these examples, the database will automatically assign and increment the book_id for each new record inserted.
PRIMARY KEY Constraints in Action
Let's see how PRIMARY KEY constraints work in practice. We'll use the employees table we created earlier:
INSERT INTO employees (employee_id, first_name, last_name, email)
VALUES (1, 'John', 'Doe', '[email protected]');
INSERT INTO employees (employee_id, first_name, last_name, email)
VALUES (2, 'Jane', 'Smith', '[email protected]');
These insertions will work fine. However, if we try to insert a duplicate employee_id:
INSERT INTO employees (employee_id, first_name, last_name, email)
VALUES (1, 'Bob', 'Johnson', '[email protected]');
This will result in an error:
Error: Duplicate entry '1' for key 'PRIMARY'
The PRIMARY KEY constraint prevents the insertion of duplicate employee_id values, maintaining data integrity.
PRIMARY KEYs and Foreign Keys
PRIMARY KEYs are crucial for establishing relationships between tables through foreign keys. Let's create a departments table and relate it to our employees table:
CREATE TABLE departments (
department_id INT PRIMARY KEY,
department_name VARCHAR(50)
);
ALTER TABLE employees
ADD department_id INT,
ADD FOREIGN KEY (department_id) REFERENCES departments(department_id);
Now, each employee can be associated with a department, and the department_id in the employees table must correspond to a valid department_id in the departments table.
Best Practices for PRIMARY KEYs
- Choose Wisely: Select a column (or columns) that will always have unique values.
- Use Surrogate Keys: When natural keys are not available or suitable, use surrogate keys (like auto-incrementing integers).
- Keep it Simple: Prefer single-column PRIMARY KEYs when possible for simplicity and performance.
- Avoid Using Real-World Data: Real-world identifiers (like SSN or phone numbers) can change and may not be truly unique.
- Consider Future Growth: Choose a data type that can accommodate future growth (e.g., BIGINT instead of INT for very large tables).
PRIMARY KEY Performance Considerations
PRIMARY KEYs have a significant impact on database performance:
- Indexing: Databases automatically create an index on PRIMARY KEY columns, speeding up searches and joins.
- Clustered Index: In some databases (like SQL Server), the PRIMARY KEY becomes the clustered index by default, affecting the physical organization of data.
- Join Operations: Tables are often joined on PRIMARY KEY columns, so choosing an efficient PRIMARY KEY can improve join performance.
Removing a PRIMARY KEY
If you need to remove a PRIMARY KEY constraint, you can use the ALTER TABLE statement:
ALTER TABLE employees
DROP PRIMARY KEY;
Be cautious when dropping PRIMARY KEYs, as this can affect data integrity and table relationships.
PRIMARY KEYs in Different Database Systems
While the concept of PRIMARY KEYs is universal in relational databases, the implementation details can vary:
- MySQL: Supports both single-column and composite PRIMARY KEYs. AUTO_INCREMENT is commonly used for generating unique identifiers.
- PostgreSQL: Offers SERIAL and BIGSERIAL types for auto-incrementing PRIMARY KEYs. It also supports sequences for more complex ID generation.
- Oracle: Uses sequences and triggers to simulate auto-incrementing PRIMARY KEYs.
- SQL Server: Provides the IDENTITY property for auto-incrementing columns.
Conclusion
PRIMARY KEYs are a cornerstone of relational database design, crucial for maintaining data integrity and establishing relationships between tables. By ensuring each record is uniquely identifiable, PRIMARY KEYs provide a solid foundation for building robust and efficient database systems.
Understanding how to properly implement and use PRIMARY KEYs is essential for any SQL developer. From simple single-column keys to more complex composite keys, the choice of PRIMARY KEY can significantly impact your database's performance and scalability.
Remember, while PRIMARY KEYs are powerful, they should be used judiciously. Always consider the specific needs of your application, the nature of your data, and potential future requirements when designing your database schema and selecting PRIMARY KEYs.
By mastering the use of PRIMARY KEYs, you'll be well-equipped to create well-structured, efficient, and reliable databases that can stand the test of time and scale with your application's needs.
Related Posts

MySQL Primary Key: Ensuring Data Integrity and Efficiency
The Primary Key is the cornerstone of a well-structured relational database in MySQL. It’s not just another constraint; it’s the...

SQL FOREIGN KEY: Linking Tables in Databases
In the world of relational databases, data is often spread across multiple tables. While this approach helps maintain data integrity...

MySQL Unique: Ensuring Data Integrity with Unique Constraints
In the world of databases, ensuring data integrity is paramount. One crucial tool for this is the UNIQUE constraint in...

SQL UNIQUE Constraint: Preventing Duplicate Values
In the world of database management, ensuring data integrity is paramount. One of the key aspects of maintaining data integrity...

SQL Auto Increment: Generating Unique IDs Automatically
In the world of database management, ensuring each record has a unique identifier is crucial. This is where SQL's auto-increment...

MySQL Foreign Key: Ensuring Data Integrity
Foreign keys are the unsung heroes of database design. They are a crucial part of maintaining referential integrity, ensuring that...
MySQL Auto Increment: Simplifying Unique IDs
Auto-increment is a powerful feature in MySQL that simplifies the creation of unique IDs for your tables. It automatically generates...

SQL Constraints: Enforcing Rules on Your Data
In the world of database management, maintaining data integrity is paramount. SQL constraints are the guardians of this integrity, ensuring...

SQL NOT NULL Constraint: Ensuring Required Data
In the world of database management, data integrity is paramount. One of the fundamental ways to maintain this integrity is...

SQL NULL Values: Handling Missing Data
In the world of databases, not all information is complete. Sometimes, we encounter missing or unknown data, and that's where...

SQL CHECK Constraint: Validating Data in Tables
In the world of database management, ensuring data integrity is paramount. One powerful tool in the SQL arsenal for maintaining...

MySQL Not Null: Ensuring Data Integrity and Preventing Errors
In the realm of databases, maintaining data integrity is paramount. One of the most effective tools for achieving this in...
- What is a PRIMARY KEY?
- Why Use a PRIMARY KEY?
- Creating Tables with PRIMARY KEYs
- Adding a PRIMARY KEY to an Existing Table
- AUTO INCREMENT with PRIMARY KEY
- PRIMARY KEY Constraints in Action
- PRIMARY KEYs and Foreign Keys
- Best Practices for PRIMARY KEYs
- PRIMARY KEY Performance Considerations
- Removing a PRIMARY KEY
- PRIMARY KEYs in Different Database Systems
- Conclusion