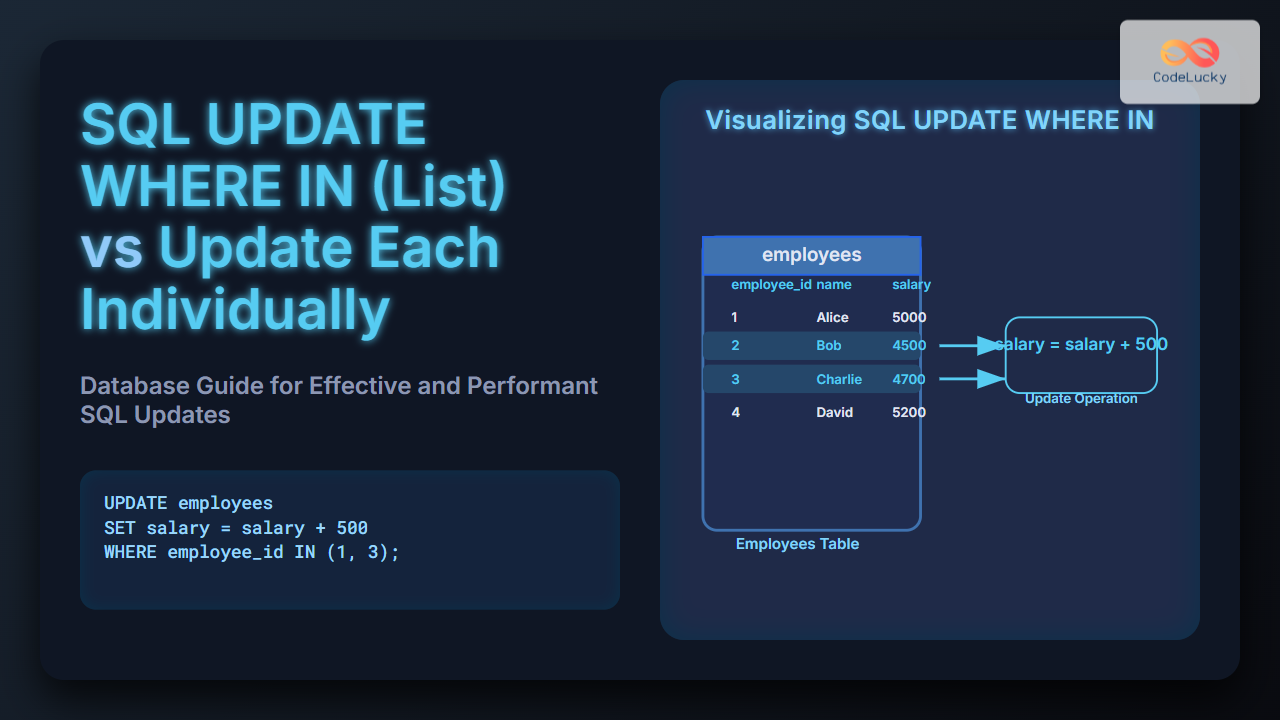
SQL's INSERT INTO statement is a fundamental command that allows you to add new records to your database tables. Whether you're populating a newly created table or updating an existing one with fresh data, mastering this statement is crucial for effective database management.
Understanding the INSERT INTO Statement
The INSERT INTO statement is used to insert new rows of data into a table in a relational database. It's one of the four basic CRUD (Create, Read, Update, Delete) operations in SQL, specifically handling the 'Create' part.
Basic Syntax
The basic syntax of the INSERT INTO statement is as follows:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
Let's break this down:
INSERT INTO: This is the keyword that tells SQL you want to insert data.table_name: This is the name of the table where you want to add the new record.(column1, column2, column3, ...): These are the columns in the table that you're inserting data into.VALUES: This keyword precedes the actual data you're inserting.(value1, value2, value3, ...): These are the values you're inserting, corresponding to the columns you specified.
🔑 Key Point: The number and order of values must match the number and order of columns specified in the INSERT INTO clause.
Practical Examples of INSERT INTO
Let's dive into some practical examples to see how INSERT INTO works in various scenarios.
Example 1: Inserting a Single Row
Imagine we have a table called employees with the following structure:
| Column Name | Data Type |
|---|---|
| employee_id | INT |
| first_name | VARCHAR |
| last_name | VARCHAR |
| hire_date | DATE |
| salary | DECIMAL |
To insert a single row into this table, we would use:
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (1001, 'John', 'Doe', '2023-06-15', 50000.00);
After executing this statement, our employees table would look like this:
| employee_id | first_name | last_name | hire_date | salary |
|---|---|---|---|---|
| 1001 | John | Doe | 2023-06-15 | 50000.00 |
💡 Pro Tip: Always use single quotes for string and date values in SQL. Double quotes are typically used for table or column names if they contain spaces or special characters.
Example 2: Inserting Multiple Rows
You can insert multiple rows in a single INSERT INTO statement, which is more efficient than executing multiple single-row inserts:
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES
(1002, 'Jane', 'Smith', '2023-06-16', 55000.00),
(1003, 'Mike', 'Johnson', '2023-06-17', 52000.00),
(1004, 'Emily', 'Brown', '2023-06-18', 53000.00);
Now our employees table looks like this:
| employee_id | first_name | last_name | hire_date | salary |
|---|---|---|---|---|
| 1001 | John | Doe | 2023-06-15 | 50000.00 |
| 1002 | Jane | Smith | 2023-06-16 | 55000.00 |
| 1003 | Mike | Johnson | 2023-06-17 | 52000.00 |
| 1004 | Emily | Brown | 2023-06-18 | 53000.00 |
🚀 Performance Boost: Inserting multiple rows in a single statement is generally faster than multiple single-row inserts, especially when dealing with large amounts of data.
Example 3: Inserting Data into Specific Columns
You don't always need to insert data into every column. If a column allows NULL values or has a default value, you can omit it from your INSERT INTO statement:
INSERT INTO employees (employee_id, first_name, last_name, hire_date)
VALUES (1005, 'David', 'Wilson', '2023-06-19');
Assuming the salary column has a default value or allows NULL, our table now looks like this:
| employee_id | first_name | last_name | hire_date | salary |
|---|---|---|---|---|
| 1001 | John | Doe | 2023-06-15 | 50000.00 |
| 1002 | Jane | Smith | 2023-06-16 | 55000.00 |
| 1003 | Mike | Johnson | 2023-06-17 | 52000.00 |
| 1004 | Emily | Brown | 2023-06-18 | 53000.00 |
| 1005 | David | Wilson | 2023-06-19 | NULL |
⚠️ Warning: Be careful when omitting columns. If a column doesn't allow NULL values and doesn't have a default value, omitting it will result in an error.
Example 4: Inserting Data Without Specifying Columns
If you're inserting data for all columns in the table, and in the same order as they appear in the table structure, you can omit the column names:
INSERT INTO employees
VALUES (1006, 'Sarah', 'Davis', '2023-06-20', 54000.00);
This approach works, but it's generally not recommended because:
- It's less readable and more prone to errors.
- If the table structure changes in the future, your
INSERTstatements might break.
🏆 Best Practice: Always specify the column names in your INSERT INTO statements for clarity and maintainability.
Advanced INSERT INTO Techniques
Now that we've covered the basics, let's explore some more advanced uses of INSERT INTO.
Inserting Data from Another Table
You can use INSERT INTO with a SELECT statement to insert data from one table into another. This is particularly useful for data migration or creating summary tables.
Let's say we have another table called new_hires with the same structure as employees:
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
SELECT employee_id, first_name, last_name, hire_date, salary
FROM new_hires
WHERE hire_date >= '2023-01-01';
This statement inserts all employees from the new_hires table who were hired in 2023 or later into the employees table.
🔍 Note: The columns in the SELECT statement should match the columns specified in the INSERT INTO clause in both number and data type.
Handling Duplicate Keys with INSERT INTO
When inserting data, you might encounter situations where you're trying to insert a record with a primary key that already exists in the table. Different database systems handle this differently, but many provide options to deal with this scenario.
MySQL: INSERT IGNORE
In MySQL, you can use INSERT IGNORE to silently skip rows that would cause duplicate key errors:
INSERT IGNORE INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (1001, 'John', 'Smith', '2023-06-21', 51000.00);
If an employee with employee_id 1001 already exists, this row will be skipped without causing an error.
PostgreSQL: ON CONFLICT DO NOTHING
PostgreSQL uses the ON CONFLICT clause to handle potential conflicts:
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (1001, 'John', 'Smith', '2023-06-21', 51000.00)
ON CONFLICT (employee_id) DO NOTHING;
This will insert the new row if there's no conflict, or do nothing if a row with employee_id 1001 already exists.
Inserting with Default Values
If you want to insert a row using default values for all columns, you can use the DEFAULT VALUES clause:
INSERT INTO employees DEFAULT VALUES;
This assumes that all columns either allow NULL values or have default values defined.
🎯 Use Case: This can be useful for tables that mostly use auto-generated values, like logs or transaction records.
Best Practices for Using INSERT INTO
To wrap up, here are some best practices to keep in mind when using INSERT INTO:
-
Always specify column names: This makes your code more readable and less prone to errors if table structures change.
-
Use parameterized queries: When inserting data from user input or external sources, use parameterized queries to prevent SQL injection attacks.
-
Batch inserts for large datasets: When inserting large amounts of data, use multi-row insert statements or batch inserts for better performance.
-
Validate data before insertion: Ensure that the data you're inserting meets your table's constraints to avoid errors.
-
Use transactions for multiple inserts: If you're inserting multiple related records, wrap the inserts in a transaction to ensure data integrity.
-
Consider using MERGE or UPSERT: For scenarios where you might need to insert or update based on existence, consider using
MERGE(SQL Server) orINSERT ... ON CONFLICT(PostgreSQL) for more efficient operations.
By mastering the INSERT INTO statement and following these best practices, you'll be well-equipped to efficiently and safely add data to your SQL databases. Remember, effective data insertion is key to maintaining accurate and up-to-date databases, which form the backbone of many applications and business processes.
Related Posts

SQL SELECT INTO Statement: Creating New Tables from Query Results
SQL's SELECT INTO statement is a powerful tool that allows you to create new tables based on the results of...

PHP MySQL Insert Data: Adding Records to Tables
In the world of web development, database operations are crucial, and inserting data is one of the most common tasks...

SQL INSERT INTO SELECT Statement: Copying Data Between Tables
SQL is a powerful language for managing and manipulating relational databases, and one of its most useful features is the...

SQL DELETE Statement: Removing Data from Tables
In the world of database management, the ability to remove data is just as crucial as adding or updating it....

SQL UPDATE Statement: Modifying Existing Records
In the world of databases, data is constantly evolving. Whether it's updating customer information, adjusting inventory levels, or modifying employee...

SQL CREATE DATABASE Statement: Setting Up Your Database
In the world of database management, creating a new database is often the first step in building a robust data...

SQL CREATE TABLE Statement: Defining New Tables
In the world of relational databases, the CREATE TABLE statement is your gateway to structuring and organizing data. This powerful...
MySQL Insert Into Select: Copying Data with Ease
The INSERT INTO SELECT statement in MySQL is a powerful tool for copying data between tables. Whether you need to...

MySQL Insert Statement: Adding Data to Your Tables
The INSERT statement is the powerhouse behind adding new data to your MySQL tables. Whether you're registering users, adding products...

PHP MySQL Update Data: Modifying Existing Records
In the world of database management, updating existing records is a crucial operation. As a PHP developer, you'll often find...

SQL SELECT Statement: Retrieving Data from Tables
SQL (Structured Query Language) is the backbone of modern database management, and at its core lies the powerful SELECT statement....

MySQL Update Statement: Modifying Your Data Safely & Efficiently
The UPDATE statement is your primary tool for modifying existing data in a MySQL database. Whether you need to correct...