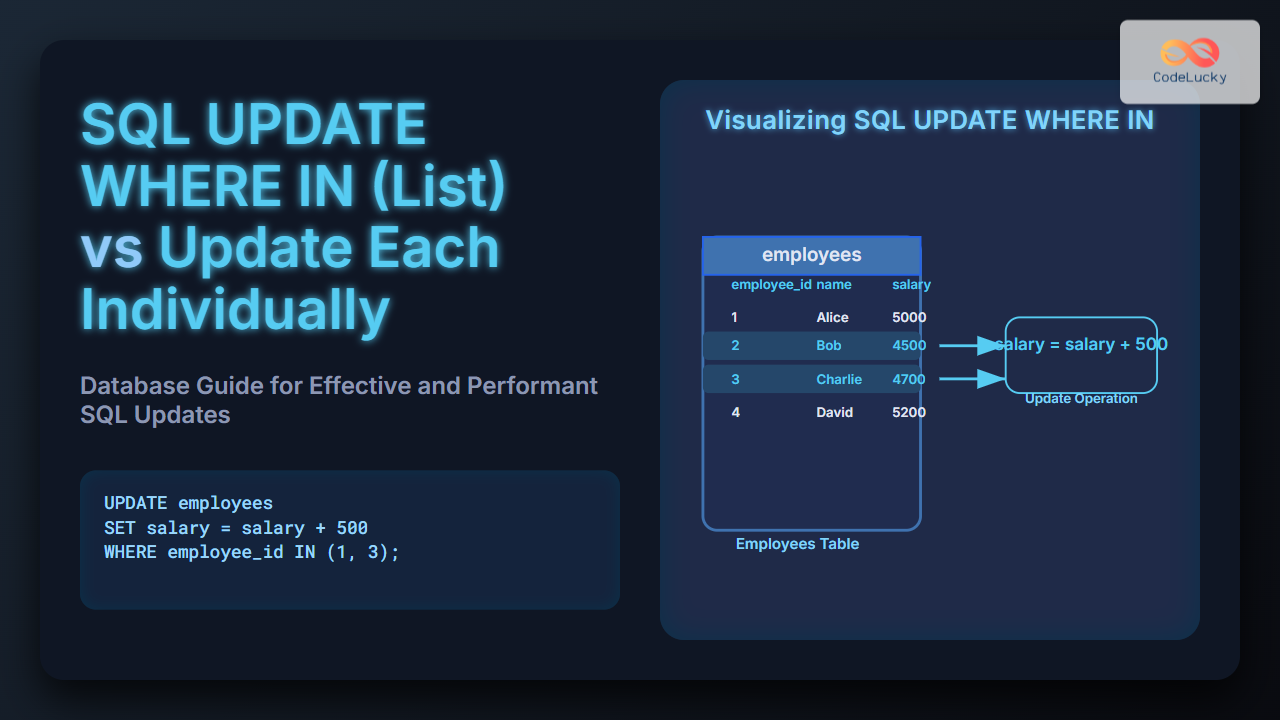
Database normalization is a crucial concept in SQL that every database designer and developer should master. It's the process of organizing data in a relational database to eliminate redundancy, reduce data anomalies, and improve data integrity. In this comprehensive guide, we'll dive deep into the world of database normalization, exploring its principles, benefits, and practical applications.
Understanding Database Normalization
🔍 Database normalization is like tidying up a messy room. It involves structuring your database tables and relationships to minimize redundancy and dependency.
The primary goals of normalization are:
- Eliminating redundant data
- Ensuring data dependencies make sense
- Facilitating data maintenance and reducing update anomalies
Normalization is typically carried out through a series of steps called normal forms. Each normal form has specific criteria that a database must meet to be considered normalized to that level.
The Normal Forms
Let's explore the most common normal forms and how they contribute to database efficiency.
First Normal Form (1NF)
The First Normal Form is the most basic level of normalization. To achieve 1NF, a table must:
- Have a primary key
- Contain atomic (indivisible) values in each column
- Eliminate repeating groups
Let's look at an example of a table that violates 1NF:
CREATE TABLE Students_Courses (
StudentID INT,
StudentName VARCHAR(50),
Courses VARCHAR(100)
);
INSERT INTO Students_Courses VALUES
(1, 'John Doe', 'Math, Physics, Chemistry'),
(2, 'Jane Smith', 'Biology, English');
This table violates 1NF because the 'Courses' column contains multiple values. To normalize it:
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
StudentName VARCHAR(50)
);
CREATE TABLE Courses (
CourseID INT PRIMARY KEY,
CourseName VARCHAR(50)
);
CREATE TABLE Student_Course (
StudentID INT,
CourseID INT,
PRIMARY KEY (StudentID, CourseID),
FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);
INSERT INTO Students VALUES
(1, 'John Doe'),
(2, 'Jane Smith');
INSERT INTO Courses VALUES
(1, 'Math'),
(2, 'Physics'),
(3, 'Chemistry'),
(4, 'Biology'),
(5, 'English');
INSERT INTO Student_Course VALUES
(1, 1), (1, 2), (1, 3),
(2, 4), (2, 5);
Now, each table satisfies 1NF, with atomic values and clear relationships.
Second Normal Form (2NF)
2NF builds upon 1NF by eliminating partial dependencies. A table is in 2NF if it's in 1NF and all non-key attributes are fully functionally dependent on the primary key.
Consider this table:
CREATE TABLE Order_Details (
OrderID INT,
ProductID INT,
ProductName VARCHAR(50),
Quantity INT,
PRIMARY KEY (OrderID, ProductID)
);
INSERT INTO Order_Details VALUES
(1, 101, 'Widget A', 5),
(1, 102, 'Widget B', 3),
(2, 101, 'Widget A', 2);
Here, ProductName depends only on ProductID, not the full primary key. To achieve 2NF:
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
Quantity INT
);
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(50)
);
CREATE TABLE Order_Product (
OrderID INT,
ProductID INT,
Quantity INT,
PRIMARY KEY (OrderID, ProductID),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Products(ProductID)
);
INSERT INTO Orders VALUES
(1, 8),
(2, 2);
INSERT INTO Products VALUES
(101, 'Widget A'),
(102, 'Widget B');
INSERT INTO Order_Product VALUES
(1, 101, 5),
(1, 102, 3),
(2, 101, 2);
Now, each non-key attribute depends on the entire primary key of its table.
Third Normal Form (3NF)
3NF further refines the database structure by eliminating transitive dependencies. A table is in 3NF if it's in 2NF and all the attributes are only dependent on the primary key.
Let's look at an example:
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
EmployeeName VARCHAR(50),
DepartmentID INT,
DepartmentName VARCHAR(50)
);
INSERT INTO Employees VALUES
(1, 'Alice', 10, 'Sales'),
(2, 'Bob', 20, 'Marketing'),
(3, 'Charlie', 10, 'Sales');
Here, DepartmentName is transitively dependent on EmployeeID through DepartmentID. To achieve 3NF:
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
EmployeeName VARCHAR(50),
DepartmentID INT,
FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID)
);
CREATE TABLE Departments (
DepartmentID INT PRIMARY KEY,
DepartmentName VARCHAR(50)
);
INSERT INTO Departments VALUES
(10, 'Sales'),
(20, 'Marketing');
INSERT INTO Employees VALUES
(1, 'Alice', 10),
(2, 'Bob', 20),
(3, 'Charlie', 10);
Now, all attributes in each table depend only on the primary key of that table.
Benefits of Database Normalization
🌟 Normalizing your database offers several advantages:
-
Reduced Data Redundancy: By eliminating duplicate data, you save storage space and reduce the risk of data inconsistencies.
-
Improved Data Integrity: With proper normalization, it's easier to maintain accurate and consistent data across the database.
-
Easier Data Maintenance: Updates, insertions, and deletions are simpler and less prone to errors in a normalized database.
-
Better Query Performance: While some queries might require joins, many queries can be more efficient on normalized tables.
-
Flexibility for Future Changes: A well-normalized database is more adaptable to future modifications and expansions.
Practical Example: Library Database
Let's apply our normalization knowledge to design a small library database system.
Initially, we might have a denormalized table like this:
CREATE TABLE Library_Books (
BookID INT,
Title VARCHAR(100),
Author VARCHAR(50),
ISBN VARCHAR(13),
BorrowerID INT,
BorrowerName VARCHAR(50),
BorrowDate DATE,
ReturnDate DATE
);
INSERT INTO Library_Books VALUES
(1, 'SQL Mastery', 'John Doe', '1234567890123', 101, 'Alice Smith', '2023-06-01', '2023-06-15'),
(2, 'Database Design', 'Jane Doe', '9876543210987', NULL, NULL, NULL, NULL),
(3, 'SQL Mastery', 'John Doe', '1234567890123', 102, 'Bob Johnson', '2023-06-10', '2023-06-24');
This table violates several normalization principles. Let's normalize it:
-- Books table
CREATE TABLE Books (
BookID INT PRIMARY KEY,
Title VARCHAR(100),
ISBN VARCHAR(13) UNIQUE
);
-- Authors table
CREATE TABLE Authors (
AuthorID INT PRIMARY KEY,
AuthorName VARCHAR(50)
);
-- Book_Author relationship table
CREATE TABLE Book_Author (
BookID INT,
AuthorID INT,
PRIMARY KEY (BookID, AuthorID),
FOREIGN KEY (BookID) REFERENCES Books(BookID),
FOREIGN KEY (AuthorID) REFERENCES Authors(AuthorID)
);
-- Borrowers table
CREATE TABLE Borrowers (
BorrowerID INT PRIMARY KEY,
BorrowerName VARCHAR(50)
);
-- Loans table
CREATE TABLE Loans (
LoanID INT PRIMARY KEY,
BookID INT,
BorrowerID INT,
BorrowDate DATE,
ReturnDate DATE,
FOREIGN KEY (BookID) REFERENCES Books(BookID),
FOREIGN KEY (BorrowerID) REFERENCES Borrowers(BorrowerID)
);
-- Inserting data
INSERT INTO Books VALUES
(1, 'SQL Mastery', '1234567890123'),
(2, 'Database Design', '9876543210987');
INSERT INTO Authors VALUES
(1, 'John Doe'),
(2, 'Jane Doe');
INSERT INTO Book_Author VALUES
(1, 1),
(2, 2);
INSERT INTO Borrowers VALUES
(101, 'Alice Smith'),
(102, 'Bob Johnson');
INSERT INTO Loans VALUES
(1, 1, 101, '2023-06-01', '2023-06-15'),
(2, 1, 102, '2023-06-10', '2023-06-24');
This normalized structure:
- Eliminates redundancy (e.g., repeated book titles and authors)
- Allows for multiple authors per book
- Separates borrower information from book information
- Tracks loan history efficiently
When to Denormalize
While normalization is generally beneficial, there are situations where some level of denormalization might be appropriate:
-
Performance Optimization: If certain queries are running too slowly due to multiple joins, denormalizing might help.
-
Reporting Needs: For complex reports that require data from multiple normalized tables, a denormalized view or table might be more efficient.
-
Read-Heavy Systems: In systems where reads vastly outnumber writes, some denormalization can improve read performance.
However, always carefully consider the trade-offs before denormalizing, as it can introduce data redundancy and update anomalies.
Conclusion
Database normalization is a powerful technique for organizing your SQL databases efficiently. By following the principles of normalization, you can create database structures that are robust, flexible, and easier to maintain.
Remember:
- Start with 1NF and progress through 2NF and 3NF
- Consider the specific needs of your application
- Balance normalization with performance requirements
By mastering database normalization, you'll be well-equipped to design databases that stand the test of time and scale with your application's needs.
🔑 Key Takeaway: Normalization is about finding the right balance between data integrity, performance, and maintainability in your database design.
Related Posts

SQL Constraints: Enforcing Rules on Your Data
In the world of database management, maintaining data integrity is paramount. SQL constraints are the guardians of this integrity, ensuring...

MySQL Best Practices | Database Design, Development, and Maintenance
Building a robust and efficient database system requires more than just knowing SQL. It involves understanding and implementing MySQL best...

SQL Data Types: Choosing the Right Type for Your Data
In the world of SQL databases, choosing the right data type is like selecting the perfect tool for a job....

MySQL RDBMS Fundamentals: Tables, Relationships, and More
Welcome to the world of relational databases! Before diving deep into MySQL commands, it's crucial to understand the fundamental concepts...

MySQL Database Creation: Your Guide to Building Databases
Creating a database is the first step in any data management journey. Whether you're developing a website, building a mobile...

PHP MySQL Create Table: Defining Database Structure
In the world of web development, databases play a crucial role in storing and managing data. When working with PHP...
MySQL Functions: Mastering Data Manipulation and Transformation
MySQL functions are the workhorses of data manipulation and transformation. They enable you to perform calculations, modify strings, manipulate dates,...
MySQL Constraints: Ensuring Data Integrity
Data is the lifeblood of any application, and ensuring its accuracy and consistency is paramount. MySQL constraints are the gatekeepers...

SQL Backup and Restore: Protecting Your Database
In the world of database management, safeguarding your data is paramount. SQL backup and restore operations are critical tools in...

SQL PRIMARY KEY: Defining Unique Identifiers in Tables
In the world of relational databases, the concept of a PRIMARY KEY is fundamental to maintaining data integrity and establishing...

SQL FOREIGN KEY: Linking Tables in Databases
In the world of relational databases, data is often spread across multiple tables. While this approach helps maintain data integrity...

MySQL Join Types: Mastering Data Relationships
Joins are the glue that binds relational databases together. They allow you to combine data from multiple tables based on...