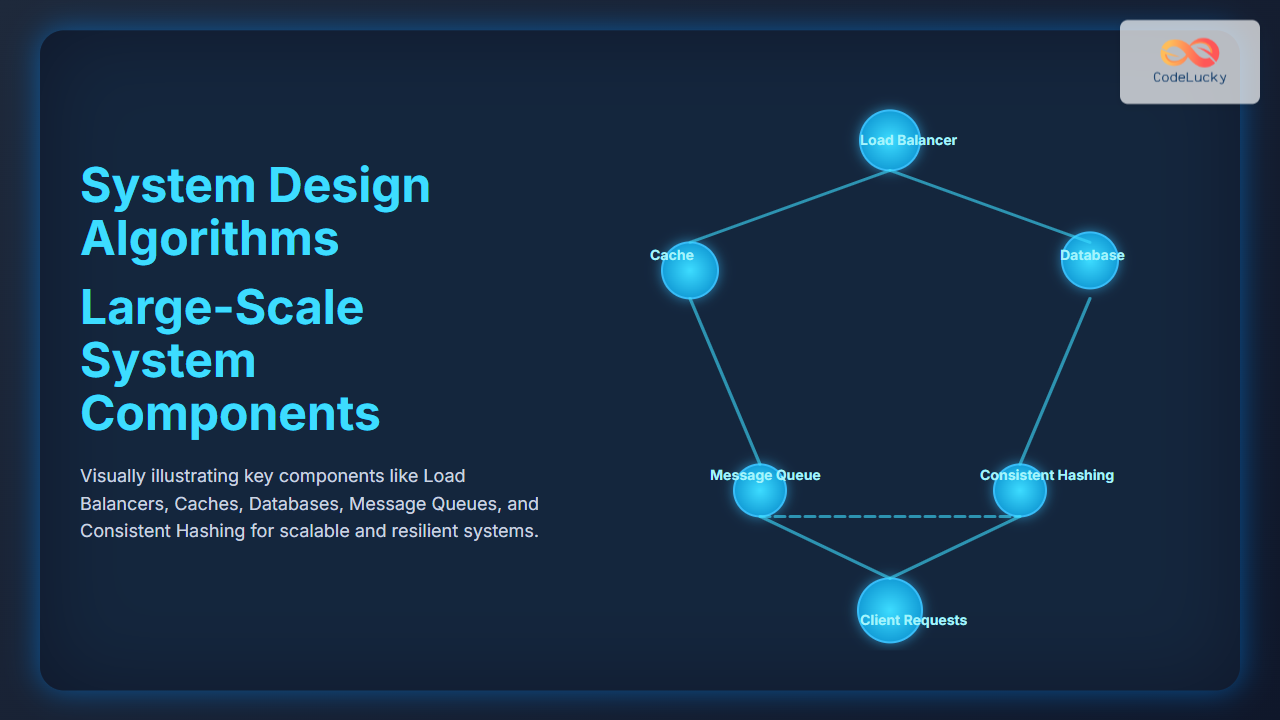
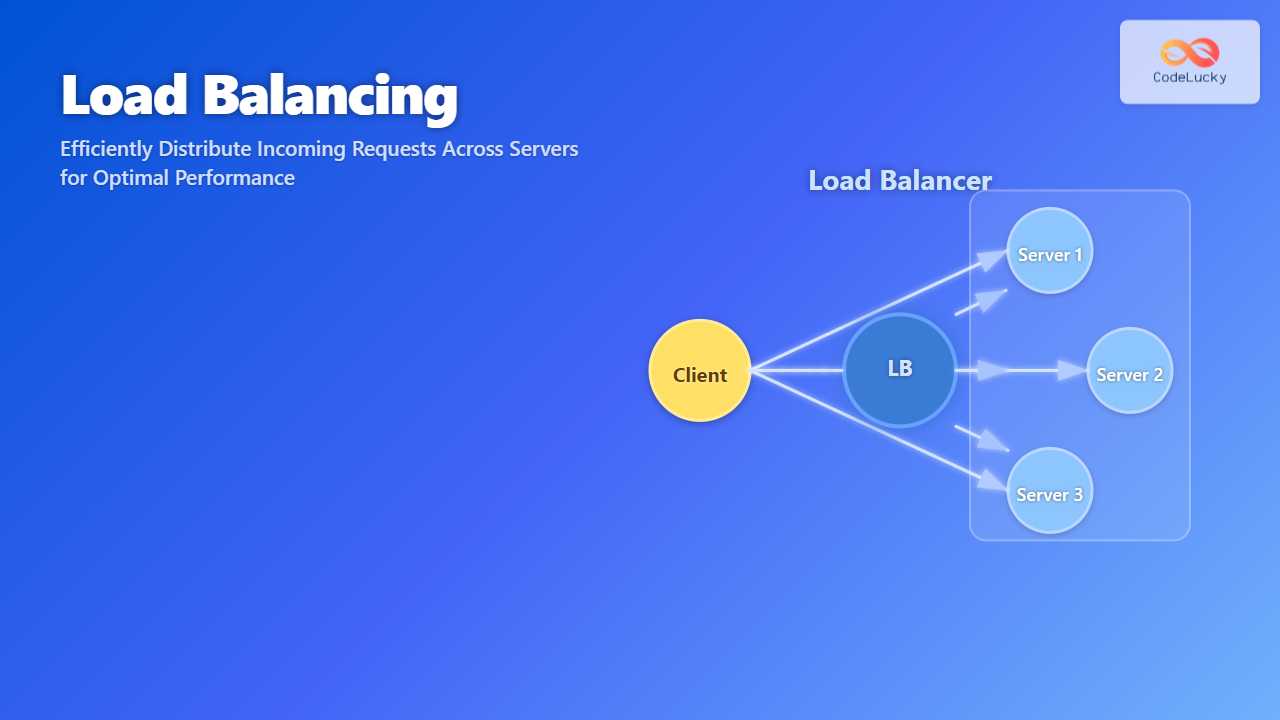
In the realm of distributed systems, replication stands as one of the most critical mechanisms for ensuring data availability, fault tolerance, and performance optimization. As systems scale across multiple nodes and geographical locations, the need for data redundancy becomes paramount to maintain service reliability and user experience.
This comprehensive guide explores the intricate world of replication in distributed systems, covering various strategies, consistency models, and implementation challenges that system architects face when designing resilient distributed applications.
What is Replication in Distributed Systems?
Replication is the process of maintaining multiple copies of data across different nodes in a distributed system. Unlike simple backup strategies, replication involves keeping synchronized copies of data that can be actively used for read and write operations, ensuring system availability even when individual nodes fail.
The primary objectives of replication include:
- Fault Tolerance: System continues operating despite node failures
- Performance Enhancement: Reduced latency through geographically distributed replicas
- Load Distribution: Spreading read/write operations across multiple nodes
- Data Availability: Ensuring data remains accessible under various failure scenarios

Types of Replication Strategies
Distributed systems employ various replication strategies based on specific requirements for consistency, availability, and partition tolerance. Understanding these strategies is crucial for making informed architectural decisions.
1. Master-Slave Replication
In master-slave replication, one node (master) handles all write operations, while multiple slave nodes maintain read-only copies of the data. This approach provides strong consistency but creates a single point of failure.
Advantages:
- Simple to implement and understand
- Strong consistency guarantees
- Clear separation of read and write operations
Disadvantages:
- Single point of failure for writes
- Limited write scalability
- Potential for slave lag during high write loads

2. Master-Master Replication
Master-master replication allows multiple nodes to accept write operations simultaneously. This approach improves write availability but introduces complexity in conflict resolution and consistency management.
Implementation Considerations:
- Conflict detection and resolution mechanisms
- Vector clocks or timestamps for ordering
- Last-writer-wins or application-specific conflict resolution
3. Peer-to-Peer Replication
In peer-to-peer replication, all nodes are equal and can handle both read and write operations. This approach maximizes availability but requires sophisticated consensus algorithms to maintain consistency.
Consistency Models in Replication
Consistency models define the level of synchronization required between replicas and directly impact system performance and reliability.
Strong Consistency
Strong consistency ensures that all replicas reflect the same data at any given time. This model provides the highest level of data integrity but may impact system availability and performance.
Implementation Techniques:
- Synchronous replication
- Two-phase commit protocol
- Consensus algorithms (Raft, PBFT)
Eventual Consistency
Eventual consistency guarantees that replicas will eventually converge to the same state, but allows temporary inconsistencies during the convergence period. This model prioritizes availability and partition tolerance.

Weak Consistency
Weak consistency provides no guarantees about when replicas will converge, offering maximum performance and availability at the cost of data consistency.
Replication Patterns and Algorithms
Chain Replication
Chain replication organizes replicas in a linear chain where writes flow from head to tail, and reads are served from the tail. This pattern provides strong consistency with good read performance.
Chain Replication Process:
- Client sends write request to chain head
- Head forwards write to next node in chain
- Write propagates through entire chain
- Tail node sends acknowledgment back to client
- Read requests are served directly from tail
Quorum-Based Replication
Quorum-based replication requires a majority of replicas to agree on read or write operations. This approach balances consistency and availability by allowing the system to operate as long as a quorum of nodes remains available.
Quorum Parameters:
- N: Total number of replicas
- R: Number of replicas required for read operations
- W: Number of replicas required for write operations
For strong consistency: R + W > N

Practical Implementation Examples
Database Replication Example
Consider a distributed e-commerce system with master-slave database replication:
Master Database Configuration:
-- Enable binary logging for replication
SET GLOBAL log_bin = ON;
SET GLOBAL server_id = 1;
-- Create replication user
CREATE USER 'repl_user'@'%' IDENTIFIED BY 'secure_password';
GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'%';
-- Show master status
SHOW MASTER STATUS;
Slave Database Configuration:
-- Configure slave connection to master
CHANGE MASTER TO
MASTER_HOST='master-db.example.com',
MASTER_USER='repl_user',
MASTER_PASSWORD='secure_password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=154;
-- Start replication
START SLAVE;
-- Check replication status
SHOW SLAVE STATUS\G
Application-Level Replication
Here’s a Python example implementing basic master-slave replication logic:
import asyncio
import json
from typing import List, Dict, Any
class ReplicationManager:
def __init__(self, master_node: str, slave_nodes: List[str]):
self.master_node = master_node
self.slave_nodes = slave_nodes
self.data_store = {}
async def write_operation(self, key: str, value: Any) -> bool:
"""Perform write operation with replication"""
try:
# Write to master first
self.data_store[key] = value
# Replicate to slaves asynchronously
replication_tasks = [
self.replicate_to_slave(slave, key, value)
for slave in self.slave_nodes
]
# Wait for majority of slaves to confirm
results = await asyncio.gather(*replication_tasks, return_exceptions=True)
successful_replications = sum(1 for r in results if r is True)
# Require majority for success
required_replicas = len(self.slave_nodes) // 2 + 1
return successful_replications >= required_replicas
except Exception as e:
print(f"Write operation failed: {e}")
return False
async def read_operation(self, key: str) -> Any:
"""Perform read operation from nearest replica"""
# In practice, route to geographically closest replica
return self.data_store.get(key)
async def replicate_to_slave(self, slave_node: str, key: str, value: Any) -> bool:
"""Replicate data to slave node"""
try:
# Simulate network call to slave node
await asyncio.sleep(0.1) # Network latency simulation
print(f"Replicated {key}={value} to {slave_node}")
return True
except Exception:
return False
# Usage example
async def main():
replication_manager = ReplicationManager(
master_node="master-1",
slave_nodes=["slave-1", "slave-2", "slave-3"]
)
# Perform write operation
success = await replication_manager.write_operation("user_1001", {
"name": "John Doe",
"email": "[email protected]",
"last_login": "2025-08-28T20:15:00Z"
})
print(f"Write operation successful: {success}")
# Perform read operation
user_data = await replication_manager.read_operation("user_1001")
print(f"Retrieved user data: {user_data}")
# Run the example
# asyncio.run(main())
Handling Replication Conflicts
When multiple replicas accept concurrent writes, conflicts inevitably arise. Effective conflict resolution strategies are essential for maintaining data integrity.
Conflict Detection Methods
Vector Clocks: Track causality relationships between events across distributed nodes.
class VectorClock:
def __init__(self, node_id: str, nodes: List[str]):
self.node_id = node_id
self.clock = {node: 0 for node in nodes}
def tick(self):
"""Increment local clock"""
self.clock[self.node_id] += 1
def update(self, other_clock: Dict[str, int]):
"""Update clock based on received message"""
for node, timestamp in other_clock.items():
self.clock[node] = max(self.clock[node], timestamp)
self.tick()
def compare(self, other_clock: Dict[str, int]) -> str:
"""Compare with another vector clock"""
self_greater = all(self.clock[node] >= other_clock[node] for node in self.clock)
other_greater = all(other_clock[node] >= self.clock[node] for node in self.clock)
if self_greater and not other_greater:
return "after"
elif other_greater and not self_greater:
return "before"
else:
return "concurrent"
Conflict Resolution Strategies
- Last Writer Wins (LWW): Simple but may lose data
- Multi-Value Resolution: Preserve all conflicting values
- Application-Specific Resolution: Custom business logic
- CRDT (Conflict-free Replicated Data Types): Mathematically guaranteed convergence

Performance Optimization Techniques
Asynchronous Replication
Asynchronous replication improves write performance by acknowledging operations before replication completes. However, this approach trades consistency for performance.
Read Replicas and Load Balancing
Implementing intelligent load balancing across read replicas can significantly improve system performance:
import random
from typing import List
class ReadReplicaBalancer:
def __init__(self):
self.replicas = []
self.health_status = {}
def add_replica(self, replica_id: str, location: str, latency: float):
"""Add a read replica to the pool"""
self.replicas.append({
'id': replica_id,
'location': location,
'latency': latency,
'load': 0
})
self.health_status[replica_id] = True
def select_replica(self, client_location: str = None) -> str:
"""Select optimal replica based on location and load"""
available_replicas = [
r for r in self.replicas
if self.health_status[r['id']]
]
if not available_replicas:
raise Exception("No healthy replicas available")
# Prefer replicas in same location
if client_location:
local_replicas = [
r for r in available_replicas
if r['location'] == client_location
]
if local_replicas:
available_replicas = local_replicas
# Select replica with lowest load
return min(available_replicas, key=lambda r: r['load'])['id']
def update_load(self, replica_id: str, load_delta: int):
"""Update replica load metrics"""
for replica in self.replicas:
if replica['id'] == replica_id:
replica['load'] += load_delta
break
Caching and Materialized Views
Implementing strategic caching at the replication layer can dramatically reduce read latency and database load.
Monitoring and Observability
Effective monitoring is crucial for maintaining healthy replication systems. Key metrics to track include:
- Replication Lag: Time delay between master and slave updates
- Throughput Metrics: Operations per second across replicas
- Error Rates: Failed replication attempts and conflicts
- Network Partition Detection: Identifying split-brain scenarios
import time
from dataclasses import dataclass
from typing import Dict
@dataclass
class ReplicationMetrics:
replica_id: str
last_update_timestamp: float
operations_per_second: float
error_count: int
lag_milliseconds: float
class ReplicationMonitor:
def __init__(self):
self.metrics: Dict[str, ReplicationMetrics] = {}
def record_operation(self, replica_id: str, success: bool):
"""Record replication operation metrics"""
current_time = time.time()
if replica_id not in self.metrics:
self.metrics[replica_id] = ReplicationMetrics(
replica_id=replica_id,
last_update_timestamp=current_time,
operations_per_second=0.0,
error_count=0,
lag_milliseconds=0.0
)
metrics = self.metrics[replica_id]
if not success:
metrics.error_count += 1
# Calculate lag (simplified example)
metrics.lag_milliseconds = (current_time - metrics.last_update_timestamp) * 1000
metrics.last_update_timestamp = current_time
def get_health_status(self, replica_id: str) -> bool:
"""Check if replica is healthy based on metrics"""
if replica_id not in self.metrics:
return False
metrics = self.metrics[replica_id]
current_time = time.time()
# Consider unhealthy if lag > 5 seconds or high error rate
time_since_update = current_time - metrics.last_update_timestamp
return time_since_update < 5.0 and metrics.error_count < 10
Security Considerations
Replication introduces additional security challenges that must be addressed:
- Encryption in Transit: Secure communication between replicas
- Access Control: Proper authentication and authorization
- Data Integrity: Checksums and verification mechanisms
- Audit Logging: Comprehensive tracking of replication activities
Common Pitfalls and Best Practices
Pitfalls to Avoid
- Ignoring Network Partitions: Always design for split-brain scenarios
- Oversynchronous Replication: Balance consistency with performance
- Inadequate Monitoring: Implement comprehensive observability
- Poor Conflict Resolution: Design clear conflict resolution strategies
Best Practices
- Design for Failure: Assume nodes will fail and plan accordingly
- Test Partition Scenarios: Regularly test network partition handling
- Implement Circuit Breakers: Prevent cascade failures
- Use Proven Algorithms: Leverage established consensus protocols
- Monitor Continuously: Implement comprehensive health checks
Future Trends and Emerging Technologies
The landscape of distributed systems replication continues to evolve with emerging technologies and patterns:
- Edge Computing Replication: Bringing data closer to users
- Multi-Cloud Replication: Cross-cloud provider strategies
- AI-Driven Optimization: Machine learning for replica placement
- Blockchain-Based Consensus: Immutable replication logs
Replication in distributed systems remains a complex but essential aspect of modern system design. By understanding the various strategies, consistency models, and implementation challenges discussed in this guide, system architects can make informed decisions that balance performance, consistency, and availability according to their specific requirements.
The key to successful replication lies in carefully analyzing your system’s specific needs, choosing appropriate consistency models, implementing robust conflict resolution strategies, and maintaining comprehensive monitoring. As distributed systems continue to evolve, mastering these replication concepts becomes increasingly valuable for building resilient, scalable applications.