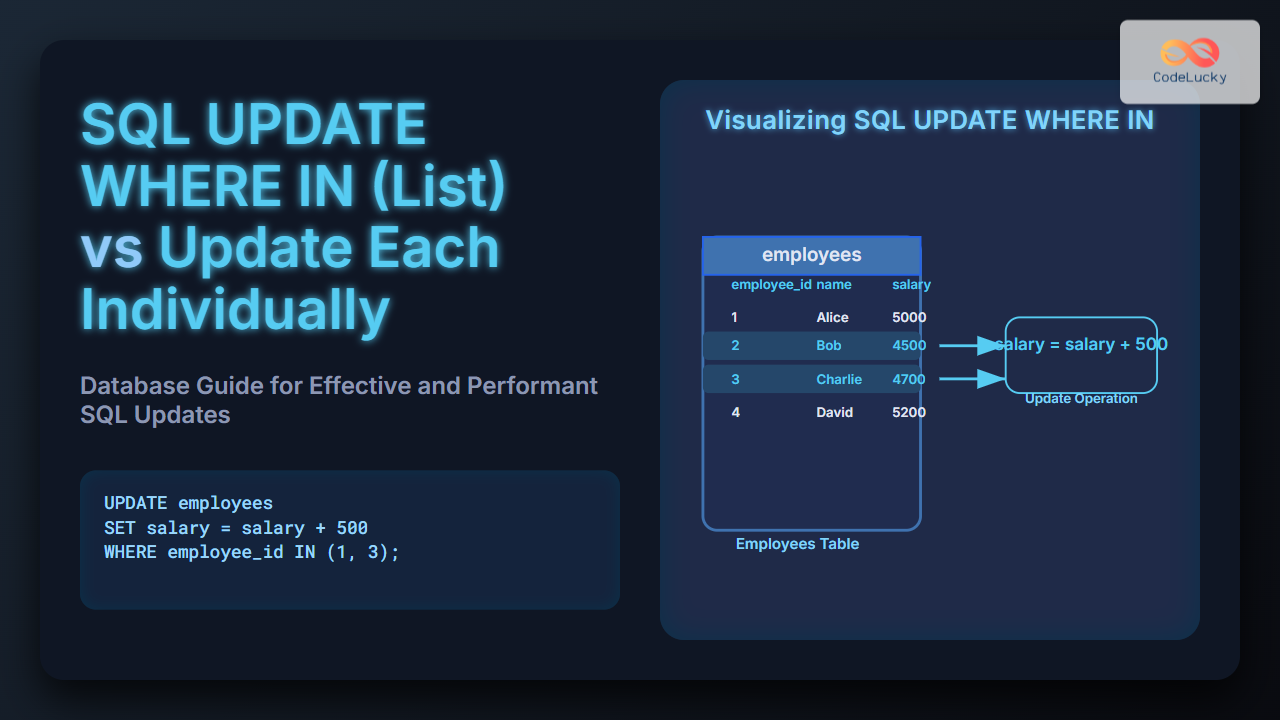
The MySQL REPLACE function is your go-to tool for efficiently substituting substrings within a string. Whether you need to standardize data, correct typos, or mask sensitive information, REPLACE provides a robust and straightforward solution. Fun Fact: 💡 String manipulation accounts for more than 30% of all database operations in data cleaning and transformation processes, making REPLACE a must-know!
Why Learn the MySQL REPLACE Function?
Before we dive into the details, let’s understand why mastering the REPLACE function is so beneficial:
🌟 Key Benefits:
- Easily find and replace specific text in your database
- Standardize inconsistent data entries
- Clean up messy or irregular text data
- Automate data transformation tasks
- Enhance data consistency and quality
🎯 Interesting Fact: The REPLACE function is optimized to process millions of records quickly, handling large-scale replacements with impressive speed.
Basic Syntax of the MySQL REPLACE Function
The basic syntax of the REPLACE function is as follows:
REPLACE(string, from_string, to_string);
Here’s a breakdown of the parameters:
string: The original string where replacements will occur.from_string: The substring to search for and replace.to_string: The substring that will replace every occurrence offrom_string.
Let’s see a simple example using Indian names and data:
SELECT REPLACE('My name is Rakesh', 'Rakesh', 'Rajesh');
Output:
| REPLACE(‘My name is Rakesh’, ‘Rakesh’, ‘Rajesh’) |
|---|
| My name is Rajesh |
In this case, all occurrences of the substring Rakesh are replaced with Rajesh.
Case Sensitivity in the REPLACE Function
By default, the REPLACE function is case-sensitive. Let’s observe this with an example:
SELECT REPLACE('My name is RAJESH', 'rajesh', 'Rajesh');
Output:
| REPLACE(‘My name is RAJESH’, ‘rajesh’, ‘Rajesh’) |
|---|
| My name is RAJESH |
Notice that because ‘rajesh’ (lowercase) is different than ‘RAJESH’ (uppercase), no replacement occurs.
To make case-insensitive replacements, use functions like LOWER() or UPPER() in combination with REPLACE().
SELECT REPLACE(LOWER('My name is RAJESH'), LOWER('rajesh'), 'Rajesh');
Output:
| REPLACE(LOWER(‘My name is RAJESH’), LOWER(‘rajesh’), ‘Rajesh’) |
|---|
| My name is Rajesh |
Using REPLACE on Database Columns
The real power of REPLACE comes to life when used directly on your database tables. Let’s see this in action:
Imagine we have a customers table:
| customer_id | first_name | last_name | |
|---|---|---|---|
| 1 | Raj | Patel | [email protected] |
| 2 | Priya | Sharma | [email protected] |
| 3 | Amit | Verma | [email protected] |
Suppose you need to replace all instances of ‘.’ with ‘_’ in the email column. You could use the following query:
SELECT
customer_id,
first_name,
last_name,
REPLACE(email, '.', '_') AS updated_email
FROM customers;
Output:
| customer_id | first_name | last_name | updated_email |
|---|---|---|---|
| 1 | Raj | Patel | raj_patel@email_com |
| 2 | Priya | Sharma | priya_sharma@email_com |
| 3 | Amit | Verma | amit_verma@email_com |
To update the actual table, use the UPDATE statement:
UPDATE customers
SET email = REPLACE(email, '.', '_');
Now, the customers table is updated with the new email formats.
Multiple Replacements with Nested REPLACE Functions
If you need to perform multiple replacements, you can nest REPLACE functions. For instance, let’s say you also want to replace all instances of ‘@’ with ‘(at)’ in the email addresses.
SELECT
customer_id,
first_name,
last_name,
REPLACE(REPLACE(email, '.', '_'), '@', '(at)') AS updated_email
FROM customers;
Output:
| customer_id | first_name | last_name | updated_email |
|---|---|---|---|
| 1 | Raj | Patel | raj_patel(at)email_com |
| 2 | Priya | Sharma | priya_sharma(at)email_com |
| 3 | Amit | Verma | amit_verma(at)email_com |
Performance Implications
While REPLACE is efficient for most operations, it’s important to consider the performance implications, particularly when dealing with extremely large datasets:
- Indexing: If you’re using
REPLACEin aWHEREclause, using it on an indexed column will disable the index, which could slow down query execution. - Data Size: On large text columns,
REPLACEoperations can be time-consuming. Consider optimizing your data storage and handling before applyingREPLACE. - Frequency: Running frequent
REPLACEoperations on the same field can slow down your database and requires careful planning.
🌟 Pro Tip: For repeated replacements, consider using stored procedures and functions. These can help you to centralize the logic and execute the changes more efficiently.

Real-World Use Cases
Let’s examine some real-world scenarios:
- Standardizing Phone Numbers:
SELECT REPLACE(phone_number, '-', ''); - Correcting Typos:
SELECT REPLACE(product_name, 'mispelled', 'misspelled'); - Masking Sensitive Data:
SELECT REPLACE(credit_card_number, SUBSTRING(credit_card_number, 1, 12), 'XXXXXXXXXXXX'); - Changing Date Formats:
SELECT REPLACE(date_column, '-', '/');
Best Practices
- Use case-insensitive methods when necessary.
- Avoid using
REPLACEdirectly on indexed columns inWHEREclauses if performance is critical. - Use nested
REPLACEcarefully. Over-nesting can make it harder to read and debug the queries. - Use stored procedures or user-defined functions for complex or frequently used replacements.
- Test your queries carefully on a small data sample first, before applying to the entire dataset.
Key Takeaways
In this article, you have learned:
- How to use the
REPLACEfunction to substitute substrings. - The importance of case-sensitivity.
- Practical applications of
REPLACEin real-world scenarios. - Performance considerations for data handling.
- How to apply multiple
REPLACEoperations.
What’s Next?
Now that you’ve gained a good grasp of string manipulation using REPLACE, you’re ready to explore more advanced topics like:
By combining REPLACE with other functions, you will be able to perform more complex data transformations, boosting your efficiency and skills in MySQL.
💡Fun fact: The REPLACE function helps many e-commerce companies keep their product data consistent, ensuring a seamless shopping experience for users worldwide!
Related Posts

MySQL String Functions: Master Text Manipulation in SQL
Strings are everywhere in databases. From names and addresses to product descriptions and user comments, text data forms a crucial...

MySQL SUBSTRING Function: Extracting Text Like a Pro
The SUBSTRING function in MySQL is your go-to tool for extracting specific parts of a string. Whether you need to...

MySQL LOWER Function: Converting Strings to Lowercase
In the world of databases, string manipulation is a common task, and one of the most frequent needs is case...

MySQL UPPER Function: Mastering Case Conversion in SQL
The UPPER function in MySQL is your go-to tool for converting strings to uppercase. Whether you need to standardize data,...

SQL String Functions: Manipulating Text Data
In the world of databases, text data plays a crucial role. Whether you're dealing with names, addresses, or product descriptions,...
Excel REPLACE Function: Complete Text Replacement Guide with Examples
The Excel REPLACE function is a powerful text manipulation tool that allows you to replace a specific portion of text...
Python String replace() Method: Replacing Substrings
The replace() method is a powerful tool in Python's arsenal for manipulating strings. It allows you to substitute occurrences of...

JavaScript String replace() Method: Replacing String
JavaScript String replace() Method: A Comprehensive Guide The replace() method in JavaScript is a powerful tool for modifying strings by...

MySQL TRIM Functions: Removing Unwanted Spaces and Characters
Data, especially text data, often comes with unwanted spaces or characters. MySQL's TRIM functions are your go-to tools for cleaning...

MySQL Regular Expressions: Advanced Pattern Matching
Regular expressions (regex) in MySQL elevate pattern matching to a whole new level! While basic pattern matching with LIKE is...

MySQL Update Statement: Modifying Your Data Safely & Efficiently
The UPDATE statement is your primary tool for modifying existing data in a MySQL database. Whether you need to correct...
MySQL Functions: Mastering Data Manipulation and Transformation
MySQL functions are the workhorses of data manipulation and transformation. They enable you to perform calculations, modify strings, manipulate dates,...