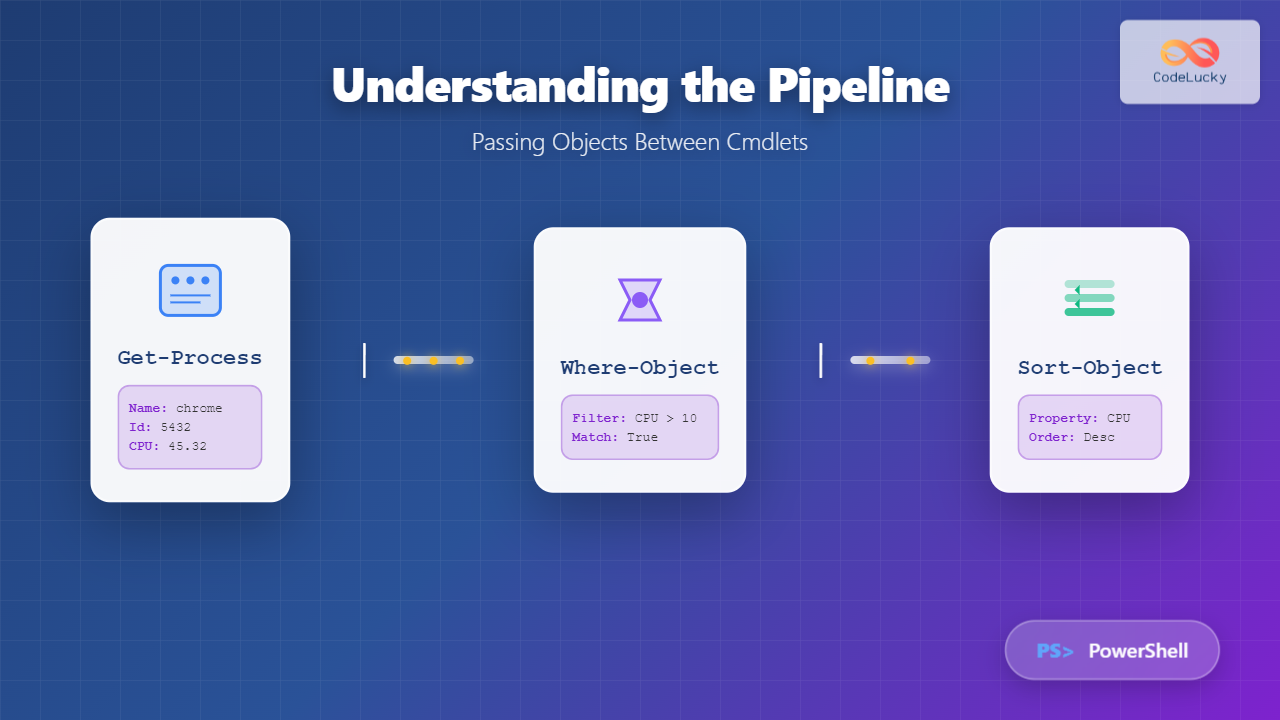
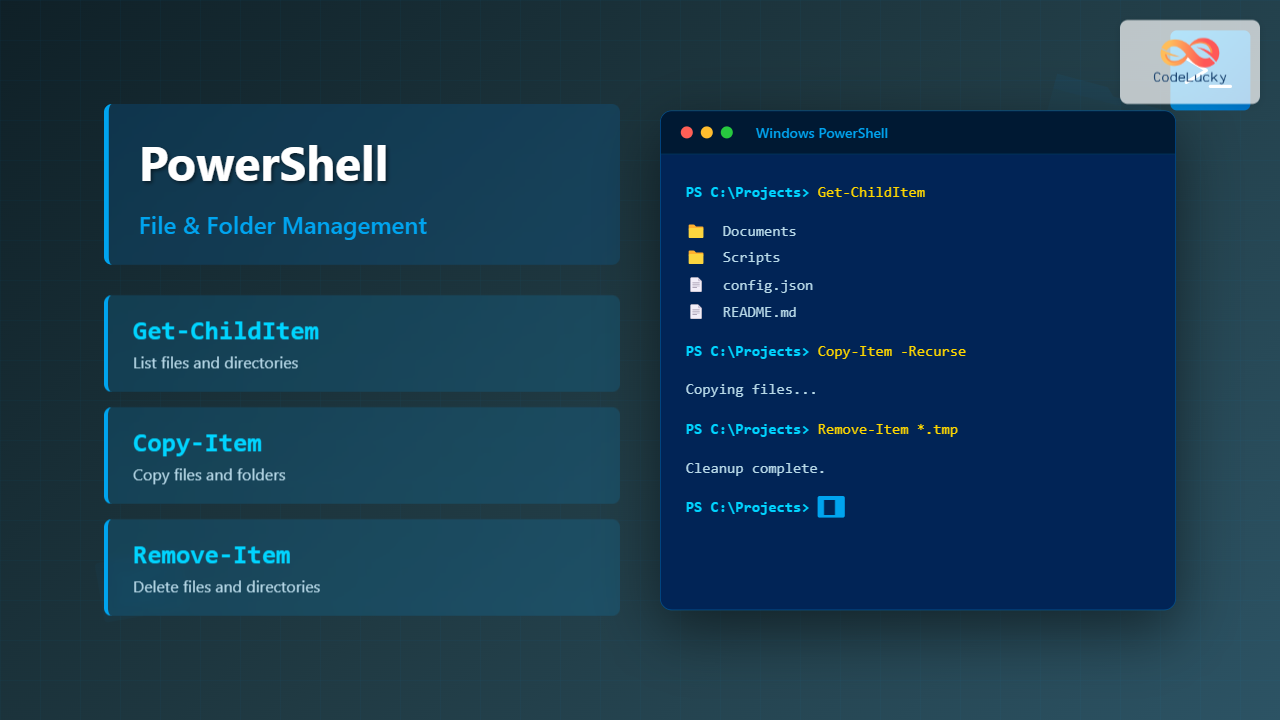
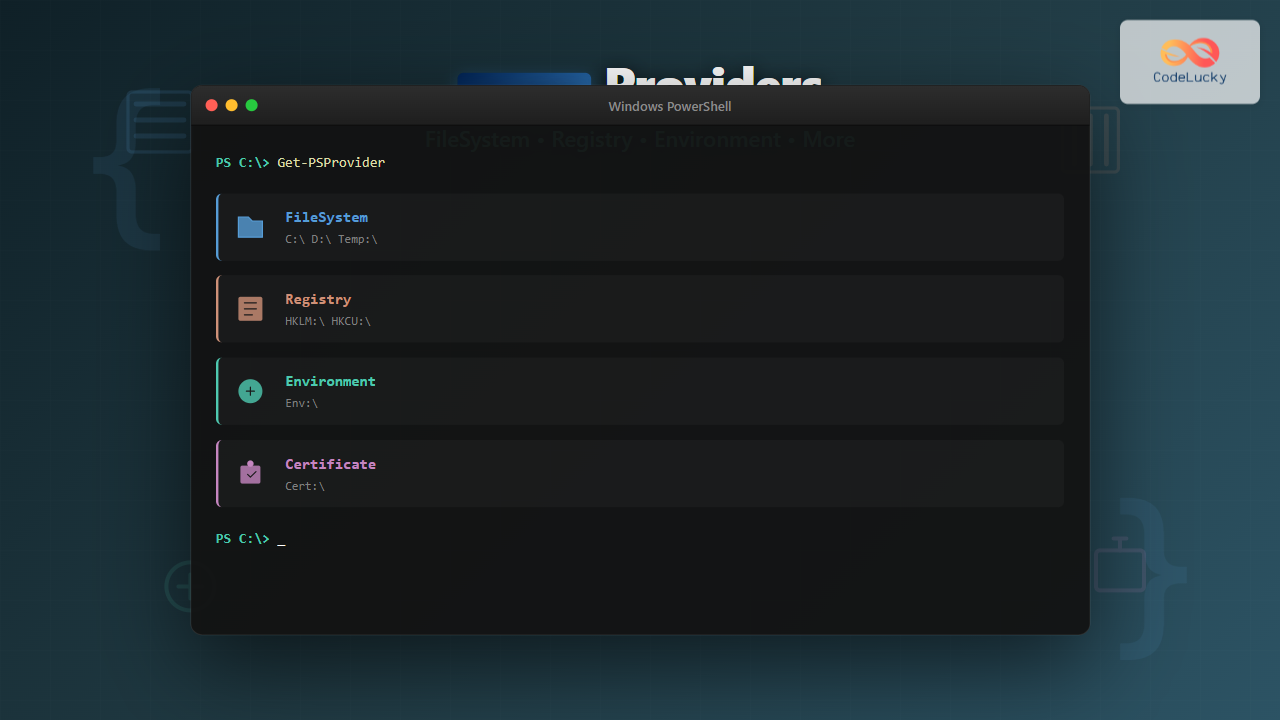
Autonomous systems represent the next evolution in operating system design, where traditional manual system administration gives way to intelligent, self-managing platforms. These sophisticated systems leverage artificial intelligence, machine learning, and advanced algorithms to automatically handle resource allocation, fault detection, security management, and performance optimization without human intervention.
What Are Autonomous Operating Systems?
An autonomous operating system is a computing platform that possesses the capability to self-manage, self-heal, and self-optimize its operations with minimal human oversight. Unlike conventional operating systems that require administrators to manually configure settings, monitor performance, and respond to issues, autonomous systems continuously analyze their environment and make intelligent decisions to maintain optimal performance.

Key Characteristics of Autonomous Systems
Self-Awareness
Autonomous systems possess comprehensive knowledge of their current state, including hardware resources, running processes, network conditions, and system health metrics. This self-awareness enables them to make informed decisions about system management.
Adaptive Behavior
These systems continuously learn from their environment and adapt their behavior accordingly. They can modify resource allocation strategies, adjust security policies, and optimize performance based on changing workloads and conditions.
Proactive Management
Rather than simply reacting to problems, autonomous systems anticipate issues before they occur. Through predictive analytics and pattern recognition, they can prevent system failures and performance degradations.
Goal-Oriented Operation
Autonomous systems operate with specific objectives in mind, such as maintaining system availability, optimizing resource utilization, or ensuring security compliance. All decisions are made in service of these goals.
Core Components and Architecture

Monitoring and Sensing Layer
This foundational layer continuously collects data from various system components including CPU usage, memory consumption, network traffic, disk I/O, temperature sensors, and application performance metrics. Advanced sensors can monitor hundreds of parameters in real-time.
Analysis Engine
The analysis engine processes collected data using machine learning algorithms, statistical analysis, and pattern recognition techniques. It identifies trends, anomalies, and potential issues that require attention.
Decision Making Unit
This component serves as the brain of the autonomous system, utilizing artificial intelligence to make complex decisions about resource allocation, security responses, and system optimizations. It weighs multiple factors and constraints to determine the best course of action.
Action Execution Layer
Once decisions are made, this layer implements the chosen actions by interfacing directly with system components, modifying configurations, reallocating resources, or triggering specific system functions.
Self-Management Capabilities
Automatic Resource Allocation
Autonomous systems excel at dynamic resource management, automatically distributing CPU cycles, memory, and storage based on real-time demand. For example, if a web server experiences sudden traffic spikes, the system can instantly allocate additional processing power and memory while scaling back resources from less critical applications.
# Example: Autonomous Resource Allocation Algorithm
class ResourceManager:
def __init__(self):
self.cpu_threshold = 0.8
self.memory_threshold = 0.9
def monitor_and_adjust(self):
current_cpu = self.get_cpu_usage()
current_memory = self.get_memory_usage()
if current_cpu > self.cpu_threshold:
self.scale_cpu_resources()
if current_memory > self.memory_threshold:
self.optimize_memory_allocation()
def scale_cpu_resources(self):
# Automatically increase CPU allocation
# Migrate processes to less loaded cores
# Adjust process priorities
pass
Self-Healing Mechanisms
When hardware failures or software crashes occur, autonomous systems can automatically detect the problem and implement recovery strategies. This might involve restarting failed services, switching to backup hardware, or redistributing workloads across healthy components.
Predictive Maintenance
By analyzing historical data and current trends, these systems can predict when hardware components are likely to fail and proactively schedule maintenance or replacements before critical failures occur.
Implementation Examples
IBM’s Autonomic Computing Initiative
IBM pioneered the concept of autonomic computing with their self-managing systems that can configure, optimize, heal, and protect themselves. Their implementation includes self-configuring applications that automatically adapt to changing environments.
Google’s Kubernetes Autopilot
Kubernetes Autopilot represents a practical implementation of autonomous system principles in container orchestration. It automatically manages cluster configuration, node provisioning, and workload optimization without manual intervention.
# Kubernetes Autopilot Configuration
apiVersion: v1
kind: ConfigMap
metadata:
name: autopilot-config
data:
auto-scaling: "enabled"
self-healing: "enabled"
optimization-level: "aggressive"
monitoring-interval: "30s"
Microsoft Azure’s Self-Healing Infrastructure
Azure implements autonomous capabilities through automatic failover mechanisms, self-repairing virtual machines, and intelligent load balancing that adapts to changing traffic patterns.
Machine Learning Integration

Anomaly Detection
Machine learning algorithms continuously analyze system behavior to establish baseline performance patterns. When deviations occur, the system can quickly identify potential issues and respond appropriately.
Predictive Analytics
Advanced ML models can forecast future system states, resource requirements, and potential failure points. This enables proactive management and prevents issues before they impact system performance.
Adaptive Learning
Autonomous systems learn from every decision and outcome, continuously refining their decision-making processes. This results in increasingly intelligent behavior over time.
# Example: ML-based Performance Prediction
import numpy as np
from sklearn.ensemble import RandomForestRegressor
class PerformancePredictor:
def __init__(self):
self.model = RandomForestRegressor(n_estimators=100)
self.features = ['cpu_usage', 'memory_usage', 'disk_io', 'network_traffic']
def train(self, historical_data):
X = historical_data[self.features]
y = historical_data['performance_score']
self.model.fit(X, y)
def predict_performance(self, current_metrics):
prediction = self.model.predict([current_metrics])
return prediction[0]
def recommend_actions(self, predicted_performance):
if predicted_performance < 0.7:
return ['increase_cpu_allocation', 'optimize_memory']
return ['maintain_current_configuration']
Security in Autonomous Systems
Automated Threat Detection
Autonomous security systems can identify and respond to cyber threats in real-time, analyzing network traffic patterns, user behavior, and system access logs to detect potential security breaches.
Self-Defending Mechanisms
When security threats are detected, these systems can automatically implement countermeasures such as isolating affected components, blocking suspicious network traffic, or strengthening authentication requirements.
Continuous Security Updates
Autonomous systems can automatically download, test, and apply security patches while ensuring system stability and minimizing downtime.
Benefits and Advantages
Reduced Administrative Overhead
Significant cost savings result from reduced need for manual system administration. Organizations can operate complex IT infrastructures with fewer personnel while maintaining higher service levels.
Improved System Reliability
Autonomous systems provide superior uptime and reliability through proactive monitoring, predictive maintenance, and automatic fault recovery mechanisms.
Enhanced Performance
Continuous optimization ensures systems always operate at peak efficiency, automatically adjusting configurations to match current workloads and requirements.
Faster Response Times
Automated decision-making enables near-instantaneous responses to changing conditions, far exceeding human reaction times.
Challenges and Limitations
Complexity and Development Costs
Building autonomous systems requires significant investment in research, development, and testing. The complexity of creating reliable AI-driven decision-making systems presents substantial technical challenges.
Trust and Control Issues
Organizations may be hesitant to relinquish control to automated systems, particularly for critical operations where mistakes could have severe consequences.
Debugging and Troubleshooting
When autonomous systems make unexpected decisions or exhibit unusual behavior, diagnosing and correcting issues can be more complex than with traditional systems.

Future Trends and Developments
Edge Computing Integration
Autonomous systems are increasingly being deployed at the network edge, enabling intelligent decision-making closer to data sources and users. This reduces latency and improves responsiveness for IoT devices and mobile applications.
Quantum-Enhanced Autonomy
Future autonomous systems may leverage quantum computing capabilities to process vast amounts of data and make complex decisions at unprecedented speeds.
Cross-System Collaboration
Next-generation autonomous systems will communicate and collaborate with each other, sharing knowledge and coordinating actions across distributed infrastructures.
Implementation Best Practices
Gradual Deployment
Organizations should implement autonomous capabilities incrementally, starting with non-critical systems and gradually expanding to more important infrastructure components as confidence and expertise grow.
Comprehensive Testing
Thorough testing in controlled environments is essential before deploying autonomous systems in production. This includes stress testing, failure scenario simulation, and validation of decision-making algorithms.
Human Oversight
Even highly autonomous systems benefit from human oversight and the ability to intervene when necessary. Implementing proper monitoring and override mechanisms ensures safety and accountability.
Continuous Monitoring
Regular assessment of autonomous system performance, decision quality, and outcomes helps identify areas for improvement and ensures systems continue to meet organizational objectives.
# Example: Monitoring Autonomous System Performance
#!/bin/bash
# Performance monitoring script for autonomous OS
LOG_FILE="/var/log/autonomous-system.log"
# Monitor decision accuracy
decision_accuracy=$(awk '/DECISION/ {correct+=$4; total++} END {print correct/total}' $LOG_FILE)
# Check response times
avg_response_time=$(awk '/RESPONSE_TIME/ {sum+=$3; count++} END {print sum/count}' $LOG_FILE)
# System health metrics
cpu_efficiency=$(cat /proc/loadavg | awk '{print $1}')
memory_utilization=$(free | awk 'NR==2{print $3/$2 * 100}')
echo "Autonomous System Performance Report"
echo "Decision Accuracy: $decision_accuracy"
echo "Average Response Time: $avg_response_time ms"
echo "CPU Efficiency: $cpu_efficiency"
echo "Memory Utilization: $memory_utilization%"
Autonomous operating systems represent a fundamental shift in how we approach system administration and management. By leveraging artificial intelligence, machine learning, and advanced automation techniques, these systems promise to deliver unprecedented levels of efficiency, reliability, and performance. While challenges remain in terms of complexity, cost, and trust, the continued advancement of autonomous technologies will likely make self-managing systems an integral part of future computing infrastructures.
As organizations increasingly rely on complex, distributed systems, the ability to automatically manage, optimize, and heal these environments becomes not just advantageous but essential. The evolution toward autonomous systems marks a significant milestone in the ongoing development of intelligent computing platforms that can adapt, learn, and evolve to meet ever-changing technological demands.